软件安全期末复习
授课:徐国胜
考试必备:概念题/简答题
名词解释题
1.整数回绕
整数在固定位宽(如32位无符号/有符号)表示下进行运算,结果超过可表示范围时会回到起始处继续计数(模2^n)。
常见风险:长度计算、内存分配大小计算出错,导致分配偏小进而引发溢出/越界写。
2.缓冲区溢出攻击
计算机向缓冲区内填充数据位数超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上,淹没局部变量、淹没返回地址。
3.恶意软件
以危害系统、窃取信息、控制主机为目的的软件统称,如病毒、蠕虫、木马、勒索软件等。常通过漏洞、钓鱼、驱动/浏览器组件等途径植入。
4.有效用户ID
在类Unix系统中用于权限判定的实际生效身份,决定进程访问文件、资源的权限;可与真实UID不同。
5.竞争条件
并发执行的多个线程、进程在访问共享资源时,由于时序不确定导致结果依赖竞速顺序,产生逻辑错误或安全漏洞。
6.ESP、EBP、EIP
EAX:常用于记录返回值,以及用来进行算数运算。
ECX:常用于计数,以及用来算术运算。
ESP:扩展堆栈指针。这个寄存器指向堆栈的当前位置,并允许通过使用push和pop操作或者直接的指针操作来对堆栈中的内容进行添加和移除。
EBP:扩展基指针。主要用与存放在进入call以后的ESP的值,便于退出的时候回复ESP的值,达到堆栈平衡目的。
EIP:扩展指令指针。在调用一个函数时,这个指针被存储在堆栈中,用于后面的使用。在函数返回时,这个被存储的地址被用于决定下一个将被执行的指令的地址。
7.代码注入
攻击者将恶意代码注入到一个应用程序中,并使得这段代码在应用程序的上下文中被执行。
8.弧注入
将控制转移到已经存在于程序内存空间中的代码中。
9.栈粉碎
由于向栈上的缓冲区写入过多数据而导致栈的正常结构被破坏的情况。
10.栈帧移位
程序重新被装入运行时,不同的环境会导致栈帧发生移位,先前查出的返回地址此时指向无效指令,静态的shellcode地址不能适应动态的内存变化。
11.虚函数
C++面向对象多态特性的重要机制。C++类的成员函数在声明时,若使用关键字virtual进行修饰,则被称为虚函数。
12.SEH
异常处理结构体。每个SEH包含两个DWORD指针,SEH链表指针,异常处理函数句柄共8个字节。
13.格式化输出
格式化输出函数参数由一个格式字符串和可变数目的参数构成,格式化字符串提供了一组可以由格式化输出函数解释执行的指令,用户可以通过控制格式字符串的内容来控制格式化输出函数的执行。
14.并行度
同一时刻实际并行执行的任务数量(例如多核同时执行多个线程)。与并发不同,并行强调同时运行。
15.堆栈缓冲区
位于栈帧中的局部数组/缓冲区(如char buf[200])。其越界写可覆盖保存的返回地址、SEH结构等,典型利用为栈溢出。
16.异常抛出
程序运行中发生异常事件并触发异常机制(如Windows SEH/VEH/未处理异常过滤器等),导致控制流转入异常处理路径;若异常处理结构可被覆盖,可能被利用执行任意代码。
简答题
1.对比植入shellcode中静态淹没返回地址与JMP ESP两种方式的优缺点。
静态淹没返回地址:用大量重复的返回地址覆盖栈上返回地址区域(喷射/淹没),通常配合NOP sled扩大命中。
优点:实现简单、对偏移误差容忍较高(可通过NOP/重复地址提高命中)。
缺点:需要可预测的跳转目标地址;地址中若含0字节等可能受字符串函数限制;遇到栈随机化/ASLR难度增加。
JMP ESP方式:返回地址覆盖为某模块中的JMP ESP指令地址,使EIP跳到ESP指向处执行栈上shellcode,破坏栈帧结构。
优点:不必精确知道shellcode绝对地址,只要能控制栈上内容;相对短跳转且结构清晰。
缺点:依赖可用的JMP ESP地址(受模块版本/ASLR/DEP影响);仍可能受坏字符限制(写返回地址时)。
2.列举动态分配缓冲区的缺点。
- 易出现堆相关漏洞:使用后释放(UAF)、双重释放、堆溢出破坏链表指针等,利用面更复杂但后果严重。
- 需要理解并依赖堆管理数据结构(如空闲链表、边界标志等),错误使用内存管理API可能引入漏洞。
- 在不同系统/版本下堆布局与分配策略差异大,漏洞复现与稳定利用更困难,环境依赖强、调试复杂、易受缓解策略影响。
- 可能导致内存耗尽:若分配大小由外部输入控制,攻击者可通过构造输入反复申请大量内存,造成拒绝服务(DoS)。
- 性能开销较大:动态分配涉及堆管理、空闲块查找及合并等操作,相比静态分配效率较低。
3.简述虚函数的实现,并试述利用虚表对虚函数开展攻击的过程。假设声明了一个类vf,具有160字节的成员变量buf和虚函数test,main函数中可以通过溢出修改虚表,据此作答。
实现机制:
(1) 编译器为含虚函数的类生成虚函数表 VTBL(函数指针数组)。
(2) 每个对象内存起始处保存虚表指针 VPTR,调用虚函数时先取VPTR定位VTBL,再取对应槽位的函数指针执行,实现运行时动态派发。
攻击思路(溢出改VPTR/改VTBL条目):
需要两个连续创建对象:[VPTR][buf(160 bytes)],[VPTR][buf(160 bytes)]
(1) 攻击者构造特殊载荷:将shellcode 写到 buff 起始位置,在 buff 末尾构造fake VTBL,其中 test指向shellcode 的地址。
(2) buff 溢出覆盖对象 VPTR,使其指向 fake VTBL。当 test 被调用时,程序通过修改的VPTR 定位到fake VTBL,进而找到其中test 地址(指向 shellcode),并把 shellcode 当 test 执行。
(3) 某些情况下也可能覆盖VTBL地址,将test函数入口地址直接改成shellcode。
4.什么是空闲内存列表,画出其关键数据结构。
空闲内存列表是堆管理器用于记录并组织空闲堆块的数据结构。当调用free释放内存时,空闲块会被插入空闲链表;当调用malloc/HeapAlloc 分配内存时,管理器会在空闲链表中查找合适大小的空闲块并将其取出或分裂。
在Windows RTL Heap 中,空闲块通常通过多个双向链表按大小类别组织(可表示为Freelist[] 的链表头数组),每个链表头为LIST_ENTRY:
当链表为空时,flink与blink都指向链表头自身。
5.不安全的API是导致字符串错误的重要原因,试列举并说明5个不安全的字符串API。
- strcpy(dst, src):不检查长度,src过长直接溢出。
- strcat(dst, src):不检查剩余空间,拼接可能越界。
- sprintf(buf, fmt, …):不限制输出长度,格式化后可能写爆buf。
- gets(buf):读取一行不做边界检查(经典栈溢出)。
- scanf(“%s”, buf):未限制宽度时可导致溢出(应使用%Ns)。
6.先写出Fronklink技术实现代码,分析它给出实现攻击者提供4字节的数据写入到同样是攻击者指定的4字节地址的实例详细过程。
1 | BK = bin; |
利用空闲链表指针(flink/blink)实现任意写的解释:释放后再写入已释放块的fp/bp(等价flink/ blink),通过后续分配 / 释放触发链表操作,完成覆盖目标地址为shellcode 地址,从而劫持控制流。
4 字节任意写过程(写“值=bp”到“地址=fp+4”):
(1) 准备一个chunk, 其起始地址+12 为GOT表上HeapFree 函数地址-8。通过溢出修改FreeList 上的某个块(假设叫fifth)的fd为fake chunk。
(2) 将一个写有shellcode 的块释放(假设叫second),second 的大小比 fifth 小, 那么会发生:成功进入while 语句, 在1 ⃝时 FD 被修改为Fakechunk 地址, 在2 ⃝时 BK被修改为HeapFree-8 地址, 在3 ⃝时BK+8, 也就是 HeapFree 被 Second 块地址替换,劫持 GOT 表。
7.请解释为什么格式化输出可能导致程序崩溃。
(1) 栈参数错位 / 读越界:格式化输出函数(如printf)是变参函数,运行时不检查参数数量和类型是否与格式字符串匹配。若格式串错误,函数会按格式说明从栈中取参数,可能读取非法数据并访问无效内存,导致程序崩溃。
(2) %n 非法写内存:格式符%n会将已输出字符数写入指定地址,若该地址非法或不可写,会引发内存访问错误。
(3) sprintf 缓冲区溢出:sprintf 不检查目标缓冲区大小,格式化结果过长会导致写越界,破坏相邻内存,从而造成程序异常或崩溃。
8.解释软件漏洞能够导致的后果有哪些?
无法正常使用、引发恶性事件、关键数据丢失、秘密信息泄漏、被安装木马病毒。
9.简述Fuzz测试的思想,并描述针对文件的Fuzz测试的步骤和流程。
技术思想:利用暴力来实现对目标程序的自动化测试,然后监视检查其最后的结果,如果符合某种情况就认为程序可能存在某种漏洞或者问题。暴力是利用不断地向目标程序发送或者传递不同格式的数据来测试目标程序的反应。
文件格式Fuzz测试的基本方法:
(1)以一个正常的文件模板作为基础,按照一定规则产生一批畸形文件。
(2)将畸形文件逐一送入软件进行解析,并监视软件是否会抛出异常。
(3)记录软件产生的错误信息,如寄存器状态、栈状态等。
(4)用日志或其他UI形式向测试人员展示异常信息,以进一步鉴定这些错误是否能被利用
10.什么时候会发生整数溢出?
当一个整数被增加超过其最大值或被减小小于其最小值时即会发生整数溢出,带符号和无符号的数都有可能发生溢出。
(AI答案)当整数运算结果超过该类型的表示范围时发生:
- 无符号:结果按模2^n回绕(回到0附近继续增加)
- 有符号:超过上界/下界产生溢出。
典型场景:len * sizeof(T)、count + header、(a+b)用于分配/拷贝长度时超过最大值,导致分配过小继而越界写(与缓冲区漏洞强相关)。
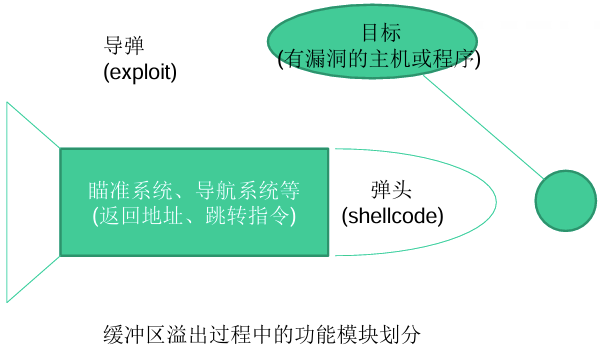
11.说说什么是shellcode和exploit。并阐述他们关系。
shellcode是一段用于执行恶意操作的代码,exploit是一种技术或方法,用于发现和利用漏洞,以执行非预期的操作。
shellcode:通称缓冲区溢出攻击中植入进程的代码,广义上可以认为恶意代码。
exploit:植入代码之前我们要做大量调试工作,弄清哪个输入会造成缓冲区溢出,计算函数返回地址和缓冲区的偏移并且淹没来使得shellcode得到执行。这个代码植入的过程就是漏洞利用,即exploit。
shellcode和exploit的关系:exploit一般以一段代码的形式出现,用于生成攻击性的网络数据包或者其他形式的攻击性输入。expliot的核心是淹没返回地址,劫持进程的控制权,之后跳转去执行shellcode。与shellcode具有一定的通用性不同,exploit往往是针对特定漏洞而言的。
软件安全基础知识
软件安全漏洞基础
1.漏洞:在软件逻辑缺陷中,有一部分如果被利用能够引起非常严重的后果。例如:SQL注入、跨站脚本、缓冲区溢出。我们通常把这类能够引起软件做一些超出设计范围的事情的bug称为漏洞。
2.漏洞与bug的区别:bug是功能性逻辑缺陷,漏洞是安全性逻辑缺陷。
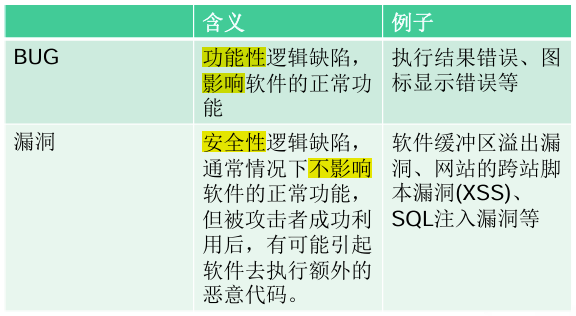
3.软件漏洞的种类(知道有哪些)
(1)缓冲区溢出漏洞:由于用户处理用户数据时使用了不限边界的拷贝,导致程序内部一些关键数据被覆盖,引发了安全问题,严重的缓冲区溢出漏洞会使得程序被利用而安装上木马或病毒。
(2)整数溢出漏洞:对于有符号的16位整数来说,它的最大值就是0x7fff,也就是十进制的32767,当赋值给一个整数的值为其最大值时,如果此时再加上1,就会发生整数型的溢出。
(3)格式化字符串漏洞:格式化字符串漏洞是由于程序的数据输出函数中对输出数据的格式解析不当而发生的。
(4)SQL注入漏洞:通过控制传递给软件数据库操作语句的关键变量来获得恶意控制软件数据库、获取有用信息或者制造恶意破坏的,甚至是控制用户计算机系统的漏洞。
4.软件漏洞的危害:无法正常使用、引发恶性事件、关键数据丢失、秘密信息泄漏、被安装木马病毒。
5.安全漏洞出现的原因:小作坊式的软件开发、赶进度带来的弊端、被轻视的软件安全测试、淡薄的安全思想、不完善的安全维护。(从开发(小作坊、安全意识、赶进度)、测试、维护的角度)
漏洞利用技术
1.shellcode与exploit的概念
Shellcode:指缓冲区溢出过程中植入进程的代码
exploit:指代码植入过程,或漏洞利用过程
(2)shellcode通常是Exploit的一部分,Exploit负责打开门,shellcode决定通过门后要做什么。
2.定位shellcode,栈帧移位与jmp esp
栈帧移位:指程序每次装入运行时,其地址会发生变换。由于移位的现象,导致静态地址的输入下,shellcode的注入攻击不能每次都成功,无法适应动态内存的变化。
Jmp esp:由于上述静态地址输入情况下的弊端,可以借助ESP来适应内存动态变化!思想如下:由于ESP在每次函数执行完,函数栈帧清除时,指向返回地址的下一个位置,该相对位置不受栈帧移位的变化!那么,可以将shellcode注入在紧跟返回地址(返回地址被覆盖为JMP ESP)之后,并通过JMP ESP的方式,调用shellcode!该方法不受内存变化的影响。示意图如下:
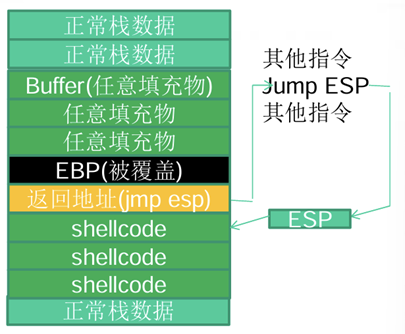
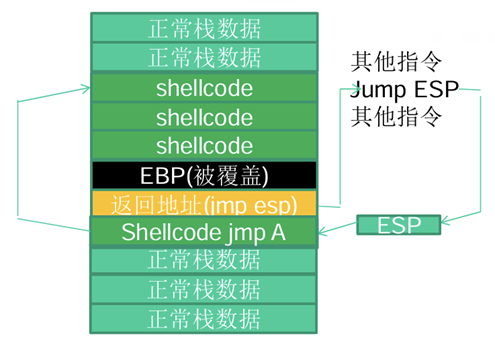
但是,上面这种shellcode放入缓冲区的布置,会有一些问题:万一系统进行push操作,可能会破坏shellcode数据!我们可以选择抬高栈顶(修改ESP),以保护shellcode!或者,在shellcode之前添加多个NOP,增加“靶子面积”。同样地,如果retn指令不确定位置,也可以放置多个retn,以确保命中。
3.缓冲区的组成
(1)填充物:可以是任何值,但是一般用NOP指令对应的0x90来进行填充,这样只要能跳进填充区,处理器最终也能顺序执行到shellcode。
(2)淹没返回地址的数据:可以是跳转指令的地址,shellcode的起始地址,或者近似的shellcode地址。(跳转进NOP填充区)
(3)shellcode:可执行的机器代码。
漏洞挖掘与模糊测试
1.Fuzz测试(考12分大题,简述思想,描述针对文件的Fuzz测试步骤流程)
(1)Fuzz的主要目的:崩溃、中断、销毁。
(2)测试用例往往是带有攻击性的畸形数据用以触发各种类型的漏洞。因为Fuzz往往可以触发一个缓冲区溢出的漏洞,但却不能实现有效的exploit。测试人员需要实时地捕捉目标程序抛出的异常、发生的崩溃和寄存器等信息,综合判断这些错误是不是真正的可利用漏洞。
(3)技术思想:利用暴力来实现对目标程序的自动化测试,然后监视检查其最后的结果,如果符合某种情况就认为程序可能存在某种漏洞或者问题。暴力是利用不断地向目标程序发送或者传递不同格式的数据来测试目标程序的反应。
(4)优缺点:优点是很少出现误报,能够迅速地找到真正的漏洞;缺点是Fuzz永远不能保证系统里已经没漏洞。即使我们用Fuzz找到了100个严重的漏洞,系统中仍然可能存在第101个漏洞。
2.文件格式Fuzz测试的基本方法步骤
(1)以一个正常的文件模板作为基础,按照一定规则产生一批畸形文件。
(2)将畸形文件逐一送入软件进行解析,并监视软件是否会抛出异常。
(3)记录软件产生的错误信息,如寄存器状态、栈状态等。
(4)用日志或其他UI形式向测试人员展示异常信息,以进一步鉴定这些错误是否能被利用。
缓冲区溢出基础
缓冲区溢出知识
1.缓冲区溢出:指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。可通过修改下列参数来利用缓冲区溢出:变量、数据指针、函数指针、栈返回地址。
系统栈的工作原理
1.内存的不同用途:成功地利用缓冲区溢出漏洞可以修改内存中的变量的值,甚至可以劫持进程,执行恶意代码,最终获得主机的控制权。
2.寄存器相关知识
(1)EAX一般用来做返回值
(2)ECX用于记数
(3)EIP:扩展指令指针。在调用一个函数时,这个指针被存储在堆栈中,用于后面的使用。在函数返回时,这个被存储的地址被用于决定下一个将被执行的指令的地址。
(4)ESP:扩展堆栈指针。这个寄存器指向堆栈的当前位置,并允许通过使用push和pop操作或者直接的指针操作来对堆栈中的内容进行添加和移除。
(5)EBP:扩展基指针。主要用与存放在进入call以后的ESP的值,便于退出的时候回复ESP的值,达到堆栈平衡的目的。
3.进程使用的内存分类(填空题,考了n次)
(1)代码区:存储着被装入执行的二进制机器代码,处理器会到这个区域取指并执行。
(2)数据区:存储全局变量等。
(3)堆区:进程可以在堆区动态地请求一定大小的内存,并在用完之后归还给堆区。动态分配和回收是堆区的特点。
(4)栈区:用于动态地存储函数之间的调用关系,以保证被调用函数在返回时恢复到父函数中继续执行。
4.函数调用的变化(知道栈帧存储顺序)

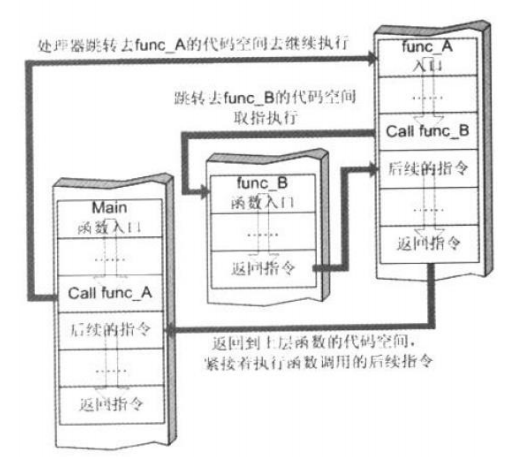
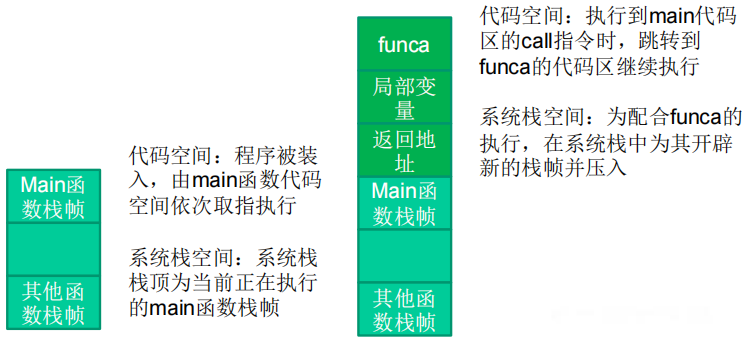


5.寄存器与函数栈帧
(1)每一个函数独占自己的栈帧空间。当前正在运行的函数的栈帧总是在栈顶。Win32系统提供两个特殊的寄存器用于标识位于系统栈顶端的栈帧。
①ESP:栈指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面的一个栈帧的栈顶。
②EBP:基址指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面的一个栈帧的底部。
③EIP:指令寄存器,其内存放着一个指针,该指针永远指向一条等待执行的指令地址。可以说如果控制了EIP寄存器的内容,就控制了进程我们让EIP指向哪里,CPU就会去执行哪里的指令。
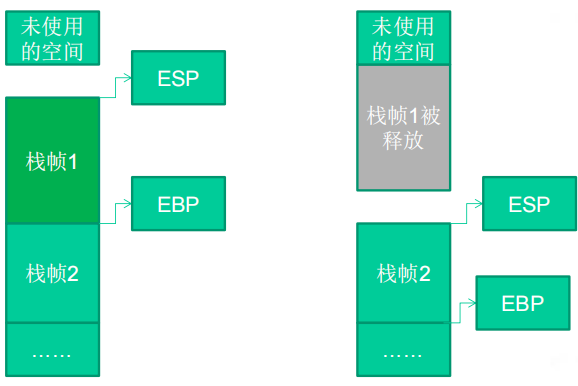
(2)在函数栈帧中,一般包含以下几类重要信息。(考了n次)
①参数
②局部变量:为函数局部变量开辟的内存空间。
③栈帧状态值:保存前栈帧的顶部和底部(实际上只保存前栈帧的底部,前栈帧的顶部可以通过堆栈平衡计算得到),用于在本帧被弹出后恢复出上一个栈帧。
④函数返回地址:保存当前函数调用前的断点信息,也就是函数调用前的指令位置,以便在函数返回时能够恢复到函数被调用前的代码区中继续执行指令。
(这样记忆:从底到高,分别是retn函数返回地址、ebp栈帧状态值、局部变量。)
6.函数调用约定与相关指令
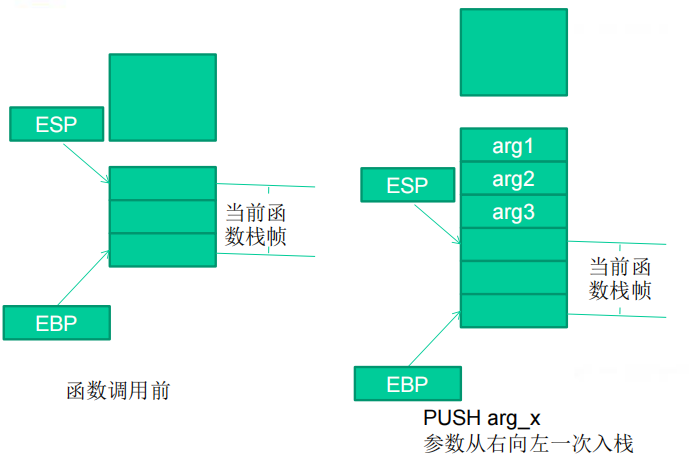
(1)函数调用步骤
①参数入栈:将参数从右向左一次压入系统栈中。
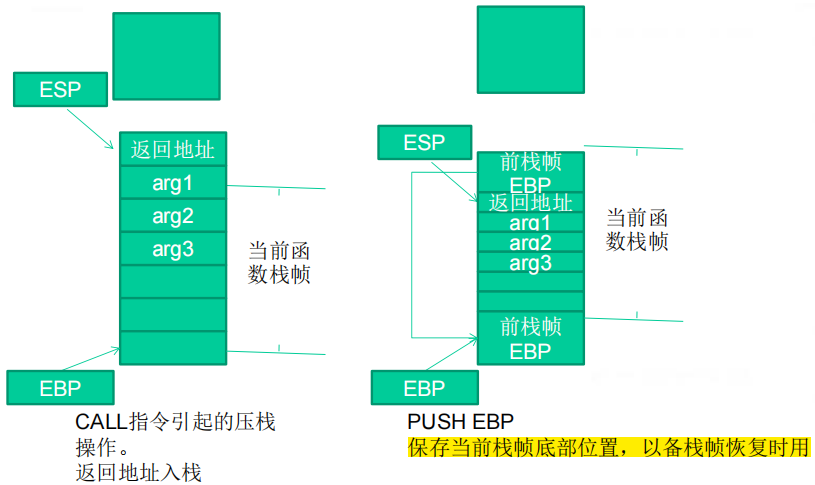
②返回地址入栈:将当前代码区调用指令的下一跳指令地址压入栈中,供函数返回时继续执行。
③代码区跳转:处理器从当前代码区跳转到被调用函数的入口处。
④栈帧调整:保存当前栈帧的状态值,以备后面恢复本栈帧时使用(EBP入栈);将当前栈帧切换到新栈帧(将ESP值装入EBP,更新栈帧底部);给新栈帧分配空间(把ESP减去所需空间的大小,抬高栈帧)。
(2)_stdcall调用约定的指令序列
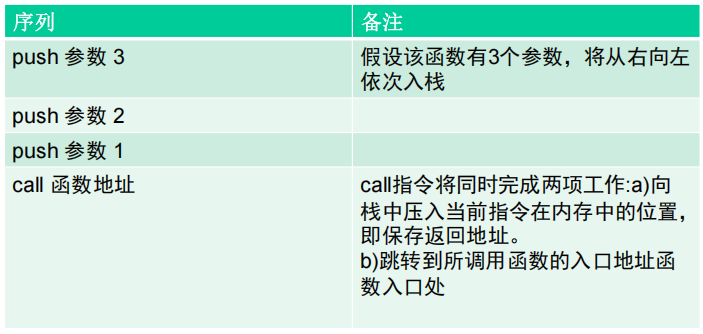
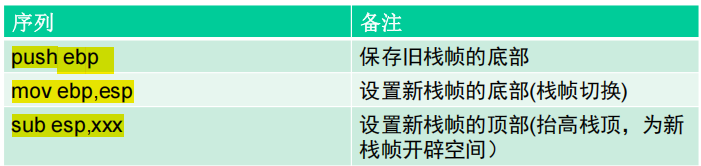
(3)函数调用时系统栈的变化过程
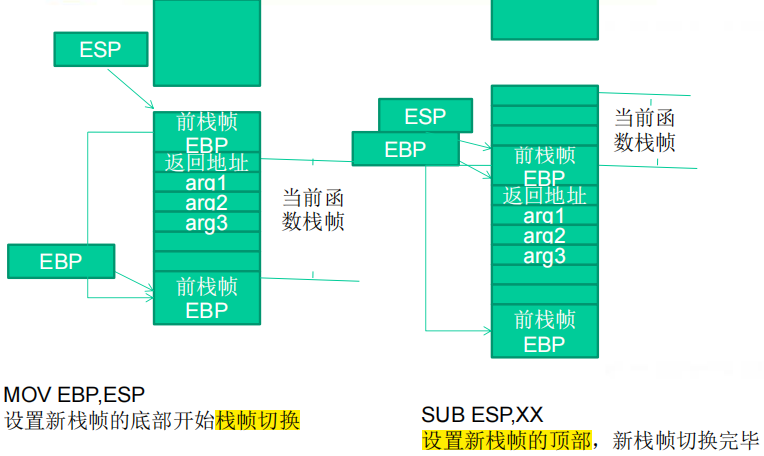
7.函数返回的步骤
(1)保存返回值:通常将函数的返回值保存在寄存器EAX中。
(2)弹出当前栈帧,恢复上一个栈帧,具体包括:在堆栈平衡的基础上,给ESP加上栈帧的大小,降低栈顶,回收当前栈帧的空间。将当前栈帧底部保存的前栈帧EBP值弹入EBP寄存器,恢复上一个栈帧。将函数返回地址弹给EIP寄存器。
(3)跳转:按照函数返回地址跳回母函数中继续执行。

修改邻接变量(实验部分)
1 |
|

1.修改邻接变量的原理
(1)authenticated为int类型,在内存中是一个DWORD,占4个字节。所以,如果让buffer数组越界,buffer[8]、buffer[9]、buffer[10]、buffer[11]将写入相邻的变量authenticated中。
(2)观察一下源代码不难发现,authenticated变量的值来源于strcmp函数的返回值,之后会返回给main函数作为密码验证成功与否的标志变量;当authenticated为0时,标识验证成功;反之则不成功。
(3)如果我们输入的密码超过了7个字符(注意:字符串截断符NULL将占用一个字节),则越界字符的ASCII码会修改掉authenticated的值。如果这段溢出数据恰好把authenticated改为0,则程序流程将被改变。实验的目的:用非法的超长密码去修改buffer的邻接变量authenticated从而绕过密码验证程序。
2.如何突破密码验证程序
(1)假如我们输入密码为7个英文字母”q”,按照字符串的关系”qqqqqqq”>”1234567”,strcmp应该返回1,即authenticated为1。
(2)那么我们经过分析可以发现,如果我们输入的是8个q,那么他的最后以为NULL会淹没authenticated的数据。
(3)Authenticated会变成0x00000000,那么判断分支则会走向正确的方向,就会绕过密码验证程序。
3.并不是所有的8位字符串都能得到想要的结果,这是为什么呢?
(1)由于authenticated的值来源于字符串比较函数strcmp的返回值。
(2)按照字符串的序关系,当输入字符串大于“1234567”时,会返回1,内存中的值为0x00000001,可以淹没地位突破验证
(3)那么当输入字符串小于“1234567”时,会返回-1,而变量在内存中的值按照双字-1的补码存放,为0xFFFFFFFF,低位被淹没后便成了0xFFFFFF00,这是的值是不能冲破验证程序的。如“01234567”就不可以。
字符串安全
背景和常见问题
1.C风格的字符串
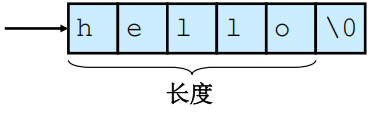
(1)C风格的字符串由一个连续的字符序列组成,并以一个空字符作为结束。
(2)一个指向字符串的指针实际上就是指向该字符串的起始字符。
(3)字符串长度指空字符之前的字节数
(4)字符串的值则是它所包含的按顺序排列的字符序列。
(5)存储一个字符串所需要的字节数是字符串的字符数加1。
3.UTF-8:UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。(有一道题)

常见的字符串操作错误
最常见的错误有(考了n次了):无界字符串复制、空结尾错误、字符串截断、差一错误、数组写入越界、不恰当的数据处理
1.无边界字符串复制
无界字符串越界写操作的有:gets()、strcpy()、strcat()、memcpy()、memset()。
(1)定义:发生于从一个无边界数据源复制数据到一个定长的字符数组时。
1 | int main(void) { |
(2)下面复制和连接字符串时也容易出现错误,因为标准strcpy()和strcat()函数执行的都是无边界复制操作。
1 | int main(int argc, char *argv[]) { |
(3)简单的解决方案:利用strlen()测试输入字符串的长度然后动态分配内存。
动态分配的代码题:
1 | int main(int argc, char *argv[]) { |
(4)C++无界字符串复制:对于下列的C++程序,如果用户输入多于11个字符,也会导致越界写。
1 |
|
(5)C++简单的解决方案
1 |
|
2.差一错误
考试题:以下程序预期的打印结果有几种情况?3
1 | int main(int argc, char* argv[]) { |
(1)source字符数组(第2行声明)为10字节,但strcpy()(第3行)却对其复制了11个字节,包括一个结尾空字符串
(2)malloc()(第4行)在堆上分配长度等于source字符串长度的内存。然而,strlen()返回的长度值并没考虑结尾空字符
(3)for循环的索引值i(第5行)是从1开始的,但C中数组索引值是从0开始的
(4)for循环结束条件是i<=11,可能比程序员期待的多迭代一次
(5)第7行的赋值操作会导致越界写
3.空结尾错误
(1)当使用C风格字符时,另一个常见的问题是字符串末尾没有正确的空字符。
练习题:给这段代码问你是什么错误
1 | int main(int argc, char* argv[]) { |
(2)从数组S2中复制不超过n个字符串(空字符后的字符不会被复制)到目标数组S1中。
1 | char *strncpy(char * restrict s1, const char * restrict s2, size_t n); |
因此,如果第一个数组S2中的前n个字符中不存在空字符,那么其结果字符串将不会是以空字符结尾的。
4.字符串截断
(1)一些限制字节数的函数通常用来防止缓冲区溢出漏洞:strncpy()代替strcpy()、fgets()代替gets()、snprintf()代替sprintf()
(2)当目标字符数组的长度不足以容纳一个字符串的内容时,就会发生字符串截断
(3)字符串截断会丢失数据,有时也会导致软件漏洞
5.数组写入越界
1 | int main(int argc, char *argv[]) { // 参数超过128,数组越界 |
由于C风格字符事实上就是字符数组,因此完全有可能在不调用任何函数的情况下做了不安全的字符串操作。
字符串问题导致的安全漏洞
字符串问题导致安全漏洞有:缓冲区溢出、程序栈、代码注入、弧注入。
1.程序栈
(1)栈通过存储下列内容来追踪程序的执行和状态:调用函数的返回地址、函数参数、局部(临时)变量
(2)在下列情况下栈需要被修改:在函数调用期间、函数初始化期间、从子例程返回时
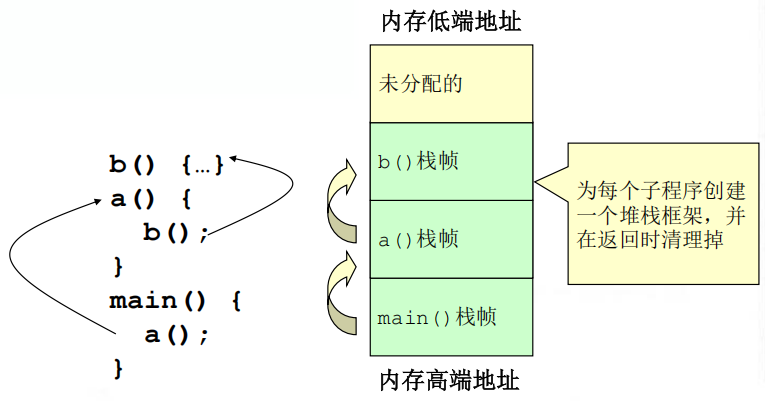
(3)堆栈支持嵌套调用,帧指由函数调用引发的压入栈的数据。
(4)当前帧的地址被存储到帧或者基址寄存器中(英特尔架构中的EBP)
(5)帧指针在栈中是一个定点的引用。
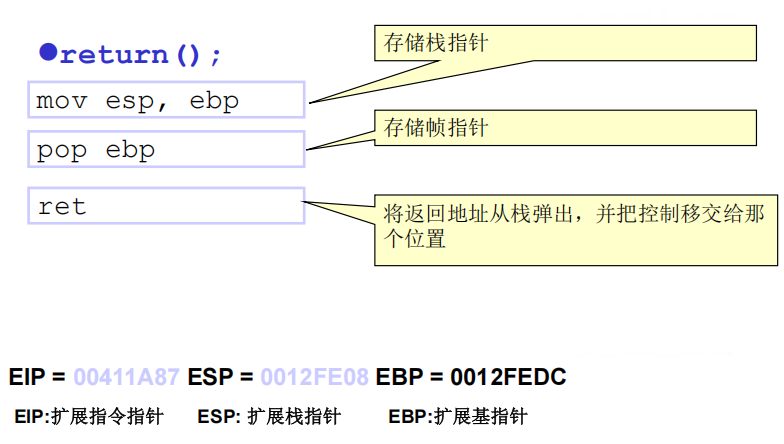
2.栈要被修改的情况
(1)子例程调用
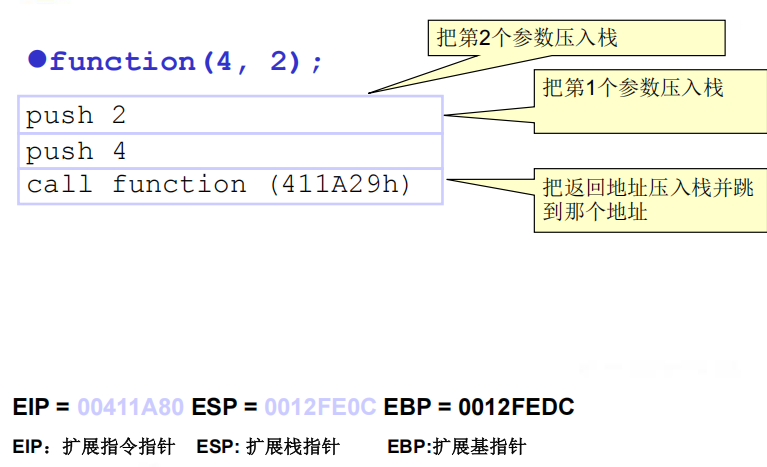
(2)子例程初始化
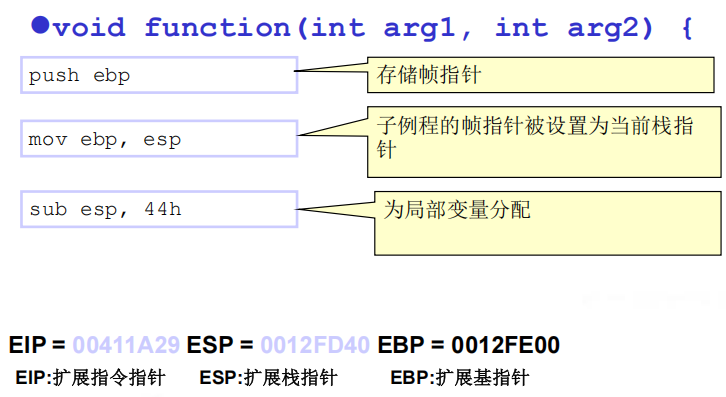
(3)从子例程返回

(4)程序案例
考试12分大题原题:根据输入的不同,列举并分析下图程序可能的结果?
1 | bool IsPasswordOK(void) { |
答题:
(1)输入”goodpass”(正确密码)。结果显示”Access granted”。因为strcmp比较字符串相等返回0,!0=1,返回true。
(2)输入其他错误密码(长度≤11字符):”wrong”、”123456”、”hello123”。显示”Access denied”并退出。因为strcmp返回非0,!非0=0,返回false。
(3)输入长度≥12字符的字符串:”AAAAAAAAAAAA”(12个A)。由于长度:12字符+\0=13字节>数组大小12字节。Password[12]只能存储11个字符+1个’\0’,输入≥12字符会导致数组越界,结果缓冲区溢出。可能导致破坏栈上相邻内存、可能修改函数返回地址、程序可能崩溃(段错误)、可能被利用执行任意代码。
①执行IsPasswordOK()函数之前,栈中的信息

②IsPasswordOK()执行时栈中的信息

③IsPasswordOK()调用后栈中的信息

3.栈粉碎:当缓冲区溢出覆写分配给执行栈内存中的数据时,就会导致栈粉碎。成功的利用这个漏洞能够覆写栈返回地址,从而在目标机器中执行任意代码。
4.代码注入
(1)攻击者创建一个恶意参数:一个蓄意构造的字符串,其中包含一个指向某些恶意代码的指针,该代码也由攻击者提供。
(2)当函数返回时,控制就被转移到了那段恶意代码。注入的代码就会以与该有漏洞的程序相同的权限运行。攻击者通常都以以root或其他较高权限运行的程序为目标。
(3)实例
通过下面的二进制输入,这个密码程序能够被用来执行任意的代码:




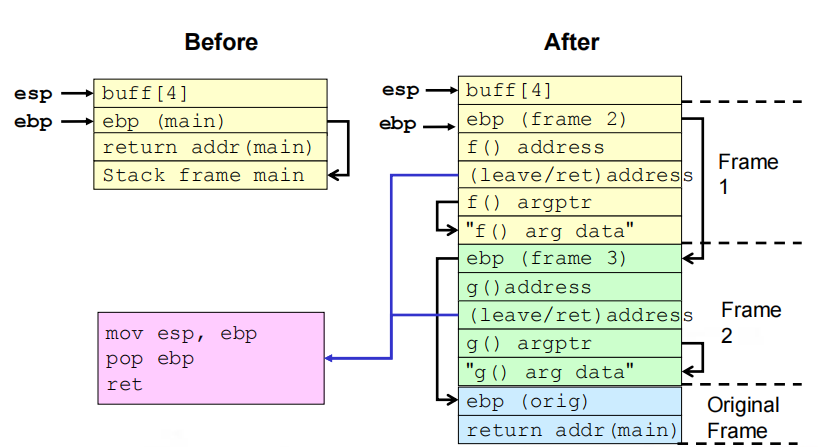
5.弧注入
(1)定义:弧注入将控制转移到已经存在于程序内存空间中的代码中。
(2)方式:在程序的控制流团中插入一段新的弧(表示控制流转移),而不是进行代码注入。可以安装一个已有函数的地址(如system()或exec()),用于执行已存在于本地系统上的程序。更复杂的攻击可能会使用这种技术。
(3)漏洞程序
1 |
|
利用:用存在的函数地址覆写返回地址;创建栈帧来链接函数调用;再现原始帧返回的程序,不进行检测并恢复执行。
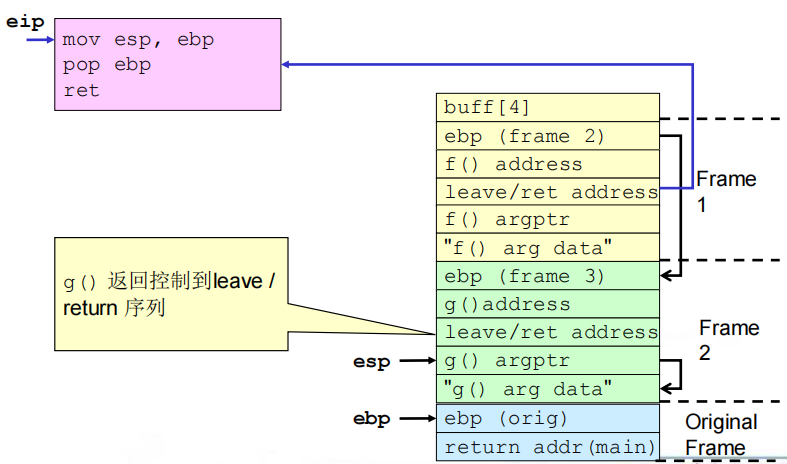
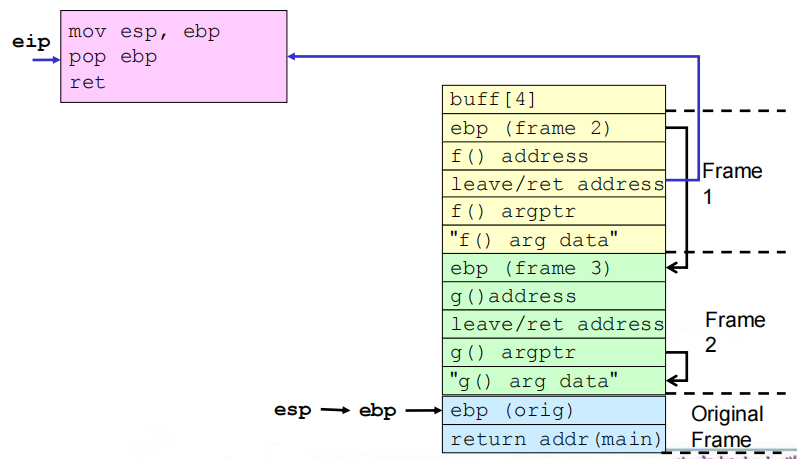
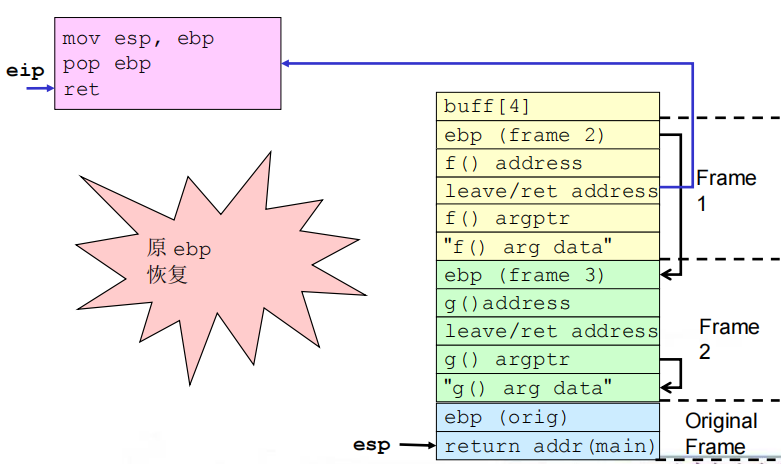
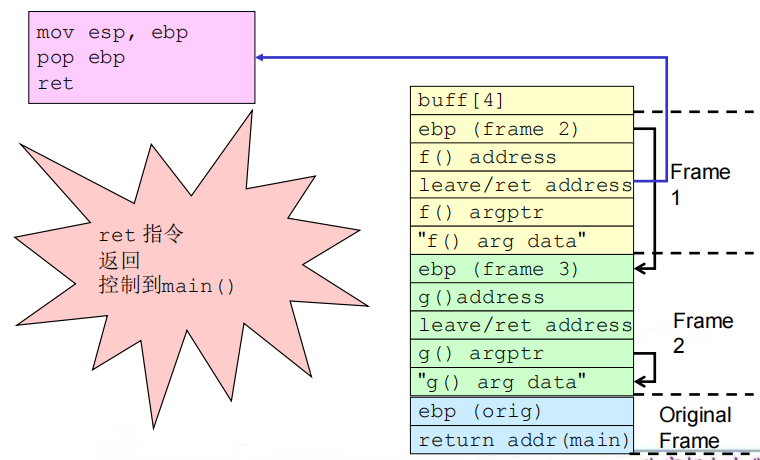
(4)相关流程
①缓冲区溢出之前及之后的栈
②get_buff()返回
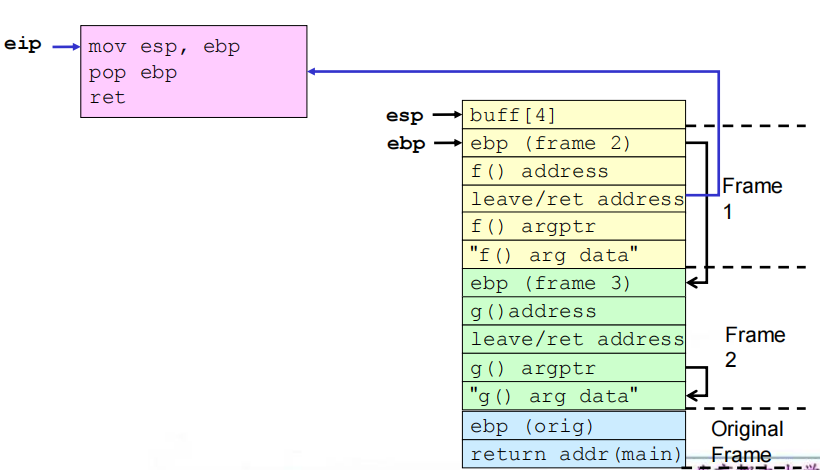
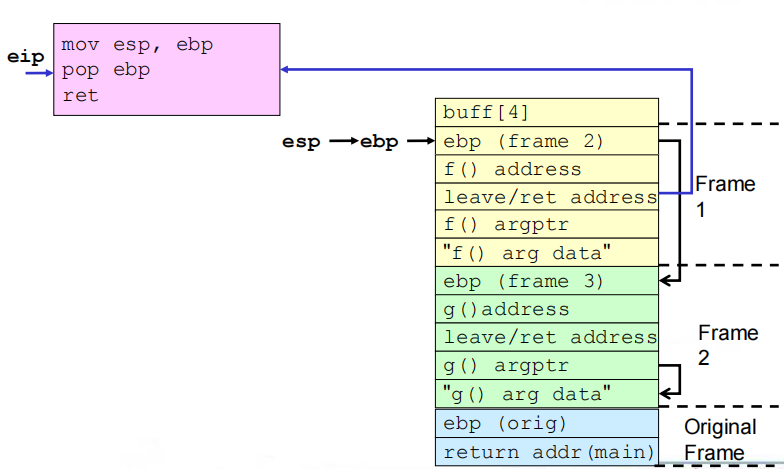
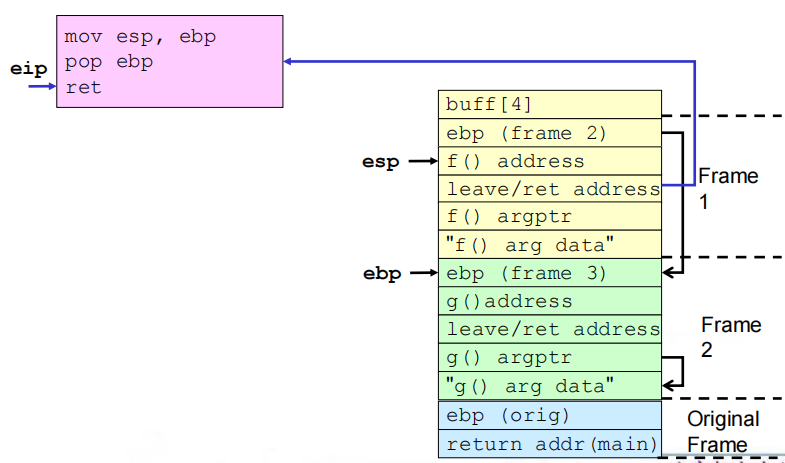
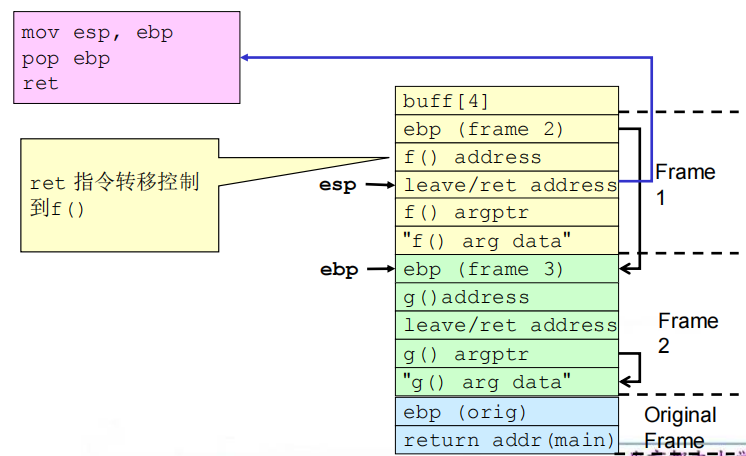
③f()返回
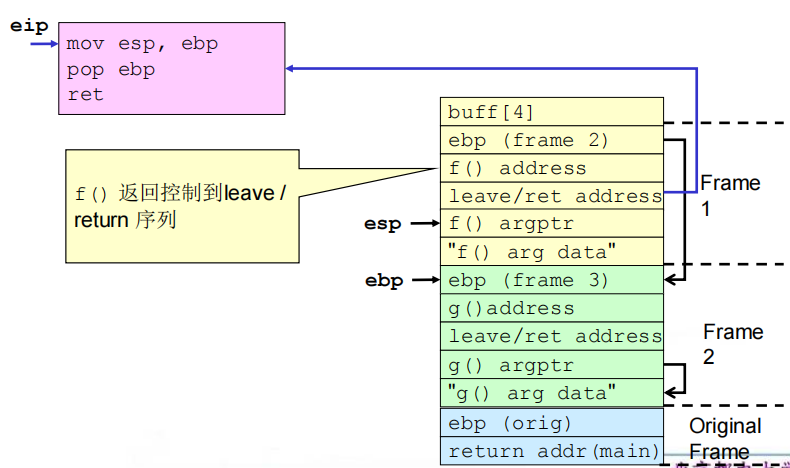
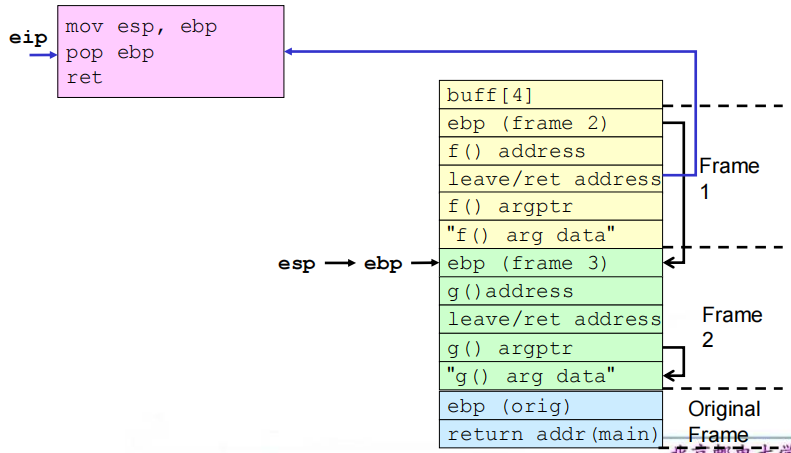
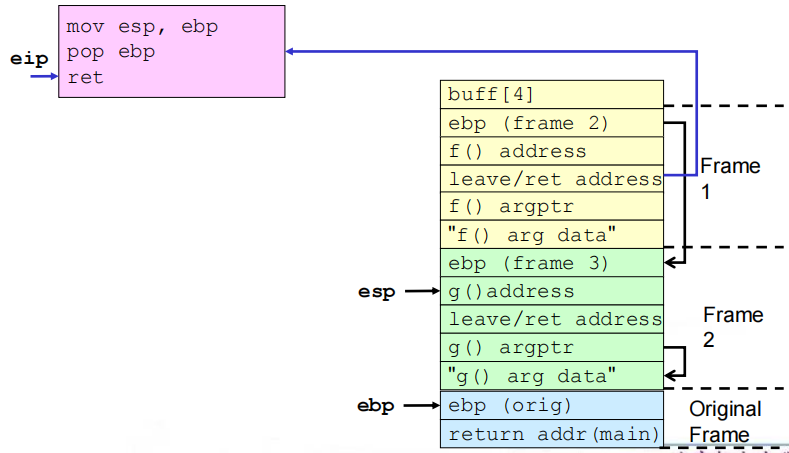
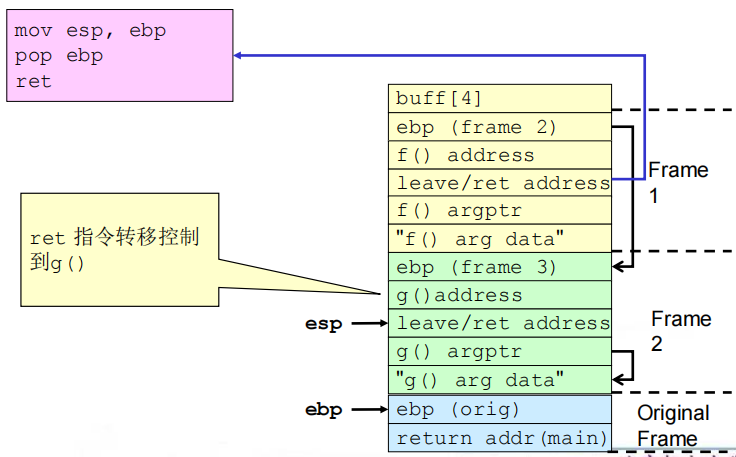
④g()返回
缓解措施
缓解措施包括:预防缓冲区溢出;侦测缓冲区溢出并安全地恢复,使得漏洞利用的企图无法得逞。
防范策略:静态分配空间、动态分配空间。
1.静态方法
静态分配缓冲区:假设一个固定大小的缓冲区。在缓冲区满了以后不可能添加再数据,因为静态的方法丢弃了超出的数据,所以实际的程序数据会丢失。因此,生成的字符串必须被充分验证。
(1)输入长度验证:缓冲区溢出通常是字符串或内存越界拷贝的结果。缓冲区溢出是确保输入数据的大小不超过其存储的最小缓冲区来可以预防。
1 | int myfunc(const char *arg) { |
(2)使用strlcpy()和strlcat()。更安全,确保结果非空结尾。
1 | size_t strlcpy(char *dst, const char *src, size_t size); |
strlcpy():从src复制空结尾的字符串到dst(直到size大小的字符)。
strlcat():把非空结尾的字符串src连接到dst末尾(不超过size的字符都能够连接到dst末尾)。
①为了阻止缓冲区溢出,strlcpy()和strlcat()接受size大小的目标字符串作为参数。对于静态分配目标缓冲区来说,这个值能够很容易地通过sizeof()操作来获取。动态缓冲区的大小不容易计算。
②两个函数都确保目标字符串对所有非零长度的缓冲区来说都是非空结尾的。
③strlcpy()和strlcat()函数返回它们希望创建的字符串的总长度。strlcpy()简单返回源字符串的总长度。strlcat()返回(连接前)目标字符串的长度加上源字符串的长度。
④为了检查字符串截断,程序需要验证返回值是否小于参数大小。如果返回的字符串被程序员截断了,知道需要存储的字符串的字节数目,可能重新分配或者重新复制。
⑤如果指定的缓冲区大小比实际的缓冲区长度长,不正确的使用这些函数仍然可能会导致缓冲区溢出。如果程序员无法验证这些函数结果,仍可能发生截断错误。
(3)使用新的安全规范函数。strcpy_s()代替strcpy()、strcat_s()代替strcat()、strncpy_s()代替strncpy()、strncat_s()代替strncat()。
①缓解缓冲区溢出攻击,默认保护与计划相关文件。
②不产生无结尾的字符串,不意外截断字符串,保存空字符结尾的字符串数据类型,支持编译时检查,使失败显现,有一个统一的函数参数和返回类型模式。
③strcpy_s()函数:把字符从源字符串复制到目标字符数组,直到并包括终止null字符。与strcpy()类似,包含一个额外的rsize_t参数类型来确定目标缓冲区的最大长度。只有当源字符串可以完全复制到目标缓冲区,且目标缓冲区没有发生溢出时,才算成功。
2.动态方法
动态地分配缓冲区:动态分配的缓冲区需要动态调整额外的内存。动态方法更好,而且不丢弃多余的数据(练习题把这个当成缺点)。主要缺点是如果输入被限制,则可能耗尽机器内存,结果导致拒绝服务攻击。
(1)SafeStr:使用一种动态分配的方式,可以在需要时自动调整字符串的大小。SafeStr通过在需要精加字符串大小的操作中,重新分配内存并移动字符串内容来实现这一点。因此,在使用这个库的时候不会发生缓冲区溢出。
①类型:SafeStr库基于safestr_t类型。该类型保存了由该指针所引用的内存部分的说明信息(例如实际长度和分配的长度),保存子指针所指向的内存之前。
②错误处理:使用XXL库来执行错误处理。为C和C++提供了异常和资产管理,调用者负责处理异常。如果没有指定异常处理程序,则默认情况下输出消息到stderr,调用abort()。依赖XXL可能会出现一个问题,因为两个库需要用来支持这个解决方案。

(2)管理字符串
①管理动态字符串:分配缓冲区。如果需要额外的内存,则重新调整内存大小。
②管理字符串操作以确保字符串操作没有导致缓冲区溢出,数据没有丢失,字符串正常终止(字符串可能是也可能不是内部空结尾)。
③缺点:无限制地消耗内存,可能导致拒绝服务攻击,性能开销。
④数据类型:使用一个不透明的数据类型管理字符串。这种类型的特征是私有的,特定实现的。

(3)黑名单:用下划线或其他无害的字符来取代危险的字符串输入。
(4)白名单:定义可接受的字符列表,删除任何不可接受的字符。
(5)数据处理:字符串管理库通过确保字符串中的所有字符属于一组预定义的安全字符,来提供一种处理数据的机制。
指针安全
网安内容
1.指针安全的概念:是通过修改指针值来利用程序漏洞的方法的统称。可以通过覆盖函数指针将程序的控制权转移到攻击者提供的shellcode。也可以修改对象指针,从而执行任意代码。
2.缓冲区溢出覆写指针条件(考了n次)
(1)缓冲区与目标指针必须分配在同一个段内。比如,缓冲区和函数指针都未初始化,因此都存在于BSS段。
(2)缓冲区必须位于比目标指针更低的内存地址处。
(3)该缓冲区必须是界限不充分的,因此容易被缓冲区溢出利用。
(4)缓冲区必须可以被缓冲区溢出利用。(废话)
3.UNIX可执行文件(包含data段和BSS段)相关概念
(1)data段包含了所有已初始化的全局变量和常数,BSS段包含了所有未初始化的全局变量
(2)已初始化的全局变量和未初始化变量分开是为了让汇编器不将未初始化的变量内容写入目标文件
要熟悉这段代码,练习题有,考某行代码存储空间在哪?
1 | static int GLOBAL_INIT = 1; /* data segment, global */ |
4.函数指针举例
考试练习题:什么情况缓冲区溢出?要记一下每行代码作用类似的。(考了n次)
argv[1]的长度大于BUFFSIZE就会发生缓冲区溢出。
1 | void good_function(const char *str) { |
程序存在漏洞可被缓冲区溢出利用。缓冲区和函数指针都未初始化,因此存在于BSS段。
1 | void good_function(const char *str) {...} |
5.对象指针举例
考试练习题:哪一行会发生任意内存写?(考了n次)
1 | void foo(void * arg, size_t len) { |
- memcpy(buff, arg, len):在溢出缓冲区后,攻击者可以覆写ptr和val
- *ptr = val:会发生任意内存写
6.修改指令指针
(1)IC存储了将要执行的下一条指令地址。
(2)IC不能被直接访问,在顺序执行代码时递增,也可以由控制转移指令间接修改。比如jmp、Conditional jumps、call、ret。
(3)静态调用对于函数地址使用立即数:指令中地址被编码。计算地址,然后放入IC。不改变执行指令,IC不会改变。
(4)IC的下一个值,存储在内存中,其可以被改变。可以通过函数指针调用(间接引用)。通过函数指针,可以间接地调用函数,即不是直接通过函数名来调用。
(5)控制IC使得攻击者可以选择要执行的代码,攻击者能够任意写的话很容易:借助指针变量进行赋值。间接的函数引用与无法在编译期间决定的函数调用可以被利用,从而使程序的控制权转移到任意代码。
1 | int _tmain(int argc, _TCHAR* argv[]) { |
上述代码反汇编:
1 | **(void)(*funcPtr)("hi");** |
问题:存储在0x00478400中的地址是0x00422479,该地址表示good_function函数的入口地址。
7.修改指令指针的目标:全局偏移表
(1)ELF默认二进制格式,GOT被包含在ELF的二进制文件的进程空间里。GOT存放绝对地址。
(3)GOT程序首次使用一个函数前,GOT入口项包含运行时连接器RTL的地址。如果该函数被程序调用,则程序的控制权被转移到RTL,然后函数的实际地址被确定且被插入到GOT中,接下来就可以通过GOT中的入口项直接调用函数。
(4)在ELF可执行文件中的GOT入口项的地址是固定的。对任何可执行进程映像而言GOT入口项都位于相同的地址。可以利用objdump命令查看某一个函数的GOT入口项位置。
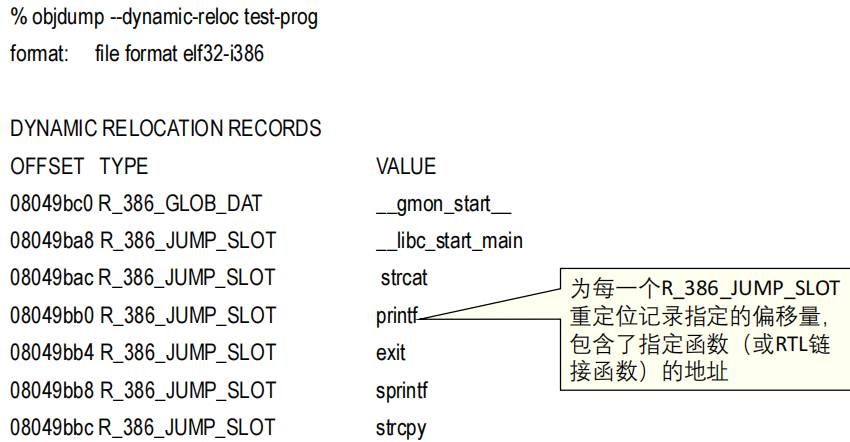
(5)如何利用GOT:攻击者需要有自己的shellcode,攻击者需要能够向任意地址写入任意值。攻击者用自己的shellcode地址覆写GOT地址(将要被使用的)
8.修改指令指针的目标
(1).dtors区
- constructor属性:函数在main()之前被调用
- destructor属性:函数将在main()执行完成后进行调用
- 构造函数和析构函数分别存储于生成的ELF可执行映像的.ctors和.dtors区中
1 | static void create(void) |
- 这两个区都有如下的布局形式:0xffffffff {function-address} 0x00000000
- .ctors和.dtors区映射到进程地址空间后,默认属性为可写
- 漏洞利用程序从未利用过构造函数,因为它们都在main()函数之前执行
- 攻击者的兴趣集中在析构函数和.dtors区上
- 可以使用objdump命令检查可执行映像中.dtors区中的内容
- 攻击者可以通过覆写.dtors区中的函数指针的地址从而将程序控制权转移到任意的代码
- 如果攻击者能够读取到目标二进制文件,那么通过分析ELF映像,很容易就能确定要覆写的确切位置。即使没有指定任何析构函数,.dtors区仍然存在。在这种情况下.dtors区中只含有头、尾标签而中间没有函数地址、仍然可以通过将尾标签0x00000000覆写未攻击者提供的外壳代码的地址,从而将控制转移过去。如果外壳代码返回,则进程将会继续调用接下来的函数直到遇到尾标签或发现错误为止。
- 对于攻击者而言,覆写.dtors区的好处在于:该区总是存在并且会映射到内存中
- 然而:.dtors仅存在于用GCC编译和链接的程序中。有时候很难找到合适的外壳代码注入点,使得在main()退出后外壳代码仍然能够驻留在内存中
(2)atexit()、on_exit()
1 |
|
- atexit()通过向一个退出时将被调用的已有函数数组中添加指定的函数完成工作
- exit()以后进先出(Last-in, First-out, LIFO)的顺序调用函数
- 数组被分配为全局性的符号:__atexit in BSD、__exit_funcs in Linux
练习题出现了以下例子:
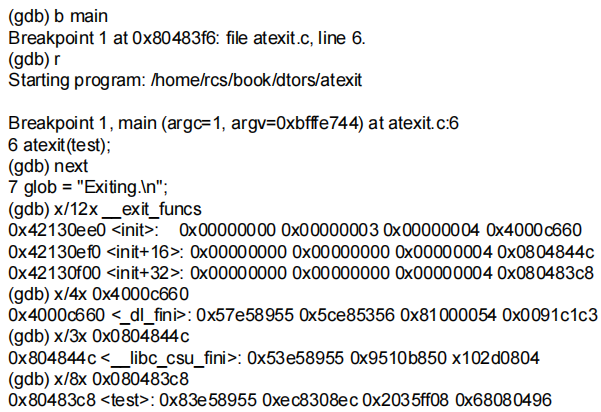
- 在该调试会话中,在main()中调用atexit()之前设了一个断点,然后运行程序。
- 接下来执行atexit()函数,注册test()函数。在test()函数注册后,显示了在__exit_funcs位置处的内存。
- 每一个函数都保存在由4个双字构成的结构中,每一个结构的最后一个双字保存着函数的实际地址。
- 示例中:3个函数已经被注册。_dl_fini()、__libc_csu_fini()、test()。攻击者可以覆写__exit_funcs结构。其中test()地址为0x080483c8.
(3)longjmp()
- 用于处理程序的低级子程序中遇到的错误和中断。setjmp()宏保存调用环境。longjmp(),siglongjmp()非局部的跳转到保存的栈环境。
- longjmp()返回控制权给调用set_jmp()的指针。
1 |
|
- jmp_buf的Linux实现:注意JB_PC域,这是攻击目标。任意写可以用缓冲区溢出shellcode的地址覆盖这个字段。
1 | typedef int __jmp_buf[6]; |
1 | longjmp(env, i) |
(4)异常处理
- 异常:函数操作中发生的意外情况。
- 三种形式异常处理程序:向量化异常处理VEH、结构化异常处理SEH、系统默认异常处理。
①SEH:通过try…catch块实现
- try块中引发的任何异常都将被匹配的catch块处理
- 如果catch块无法处理该异常,那么它将被传回之前的范围块
- __finally被调用来清理由try块说明的任何东西。
②栈帧初始化需注意:异常处理程序地址紧跟在局部变量之后。如果栈变量发生缓冲区溢出,那么异常处理程序地址就可以被覆写。
- 攻击者可以覆写异常处理程序地址,替换TEB中的指针。TEB包含已注册的异常处理程序列表。攻击者仿造一个列表入口作为攻击代码的一部分,利用任意内存写技术修改第一个异常处理程序域。
- Windows为进程提供了一个全局异常过滤器和处理程序,如果之前的异常处理程序都没能处理异常,那么该处理程序就会被调用。
- 往往为整个进程实现一个未处理异常,使得程序能够优雅地处理非预期的错误或者只是为了调试方便。
- 未处理异常过滤器函数利用SetUnhandledExceptionFilter()函数进行设置。
- 如果攻击者利用任意内存写技术覆盖了某特定内存地址,则未处理异常过滤器可以被重定向去执行任意代码。
(5)虚函数
①面向对象编程的重要特性,允许函数调用的动态绑定。
②虚函数是类成员函数,用virtual关键字声明,可由派生类中的同名函数重写,函数调用在运行时解析。
③虚函数实现:虚函数表VTBL。VTBL是一个函数指针数组,用于在运行时派发虚函数调用在每一个对象的头部,都包含一个指向VTBL的虚指针VPTR。VTBL含有指向虚函数的每一个实现的指针。
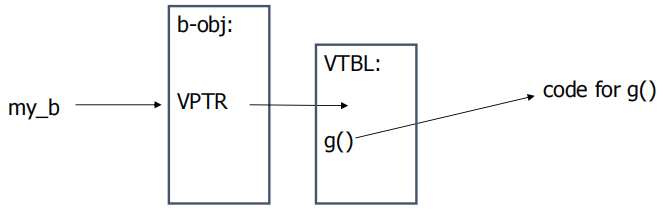
④攻击者可以覆写VTBL中的函数指针,改写VPTR使其指向其他任意的VTBL。
⑤攻击者可以通过任意内存写或者利用缓冲区溢出直接写入对象实现这一操作。
10.缓解措施
(1)消除允许内存被不正确地覆写的漏洞。这些错误出现在:覆写对象指针、常见的动态内存管理错误、字符串格式化漏洞。
(2)减少目标暴露:W^X写或执行,只可其一。降低有漏洞的进程的权限。内存区域要么可写要么可执行,但不可同时二者兼备。
(3)栈探测仪。能够保护通过溢出栈缓冲区来覆写栈指针或者其他保护区域的漏洞利用。不能保护包括栈段在内的任何位置发生缓冲区溢出。修改的漏洞利用:变量、对象指针、函数指针。
11.虚函数攻击
(1)背景:多态是面向对象的一个重要特性,在C++中这个特性主要靠对虚函数的动态调用来实现。
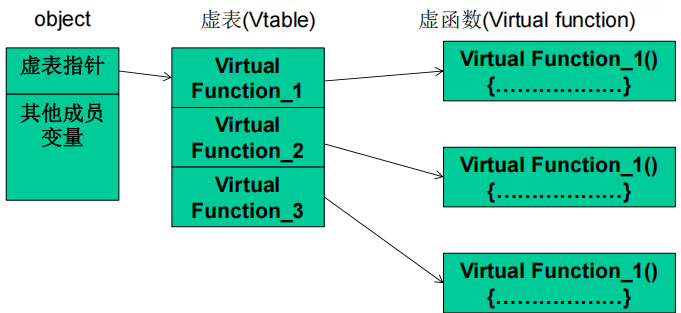
(2)相关理解:
①C++类的成员函数在声明时,若使用关键字virtual进行修饰,则被称为虚函数。
②一个类中可能有很多个虚函数。虚函数的入口地址被统一保存在虚表中。
③对象在使用虚函数时,先通过虚表指针找到虚表,然后从虚表中取出最终的函数入口地址进行调用。
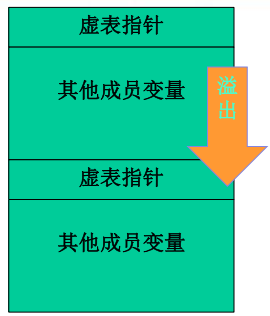
④虚表指针保存在对象的内存空间中,紧接着虚表指针的是其他成员变量。
⑤虚函数只有通过对象指针的引用才能显示出其动态调用的特性。
虚函数攻击代码:
1 | char[] shellcode="......"; |
1 | void main(void) |
(3)流程:
①虚表指针位于成员变量char buf[200]之前,程序中通过p_vtable = overflow.buf-4定位到这个指针。
②修改虚表指针指向缓冲区的0x0042E430处(第一次得不到,需要通过调试得到)。
③程序执行到p->test()时,将按照伪造的虚函数指针去0x0042E430寻找虚表,这里正好是缓冲区里shellcode的末尾。在这里填上shellcode的起始位置0x0042E35C作为伪造的虚函数入口地址,程序将最终跳去执行shellcode。

(4)由于虚表指针位于成员变量之前,溢出只能向后覆盖数据,所以很可惜这种利用方式在栈溢出场景下有一定局限性。当然,如果内存中存在多个对象且能够溢出到下一个对象空间中去,连续性覆盖还是有攻击的机会的,比如下图这种情况。
信安补充解释内容
1.SEH相关知识:SEH即异常处理结构体,它是Windows异常处理机制所采用的重要数据结构。每个H包含两个DWORD指针:SEH链表指针和异常处理函数句柄,共8个字节。


2.SEH处理流程
(1)SEH结构体存放在系统栈中。当线程初始化时会自动向栈中安装一个SEH,作为线程默认的异常处理。
(2)如果程序源代码中使用了_try{}_except{}或者Assert宏等异常处理机制,编译器将最终通过向当前函数栈帧中安装一个SEH来实现异常处理。
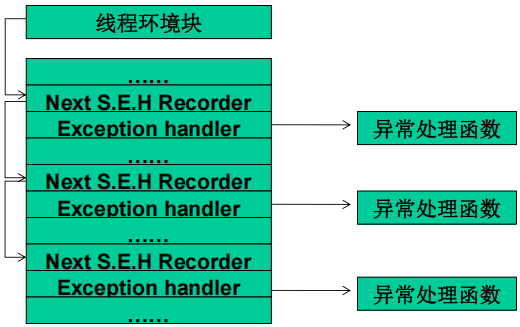
(3)栈中一般会同时存在多个SEH。栈中的多个SEH通过链表指针在栈内由栈顶向栈底串成单向链表,位于链表最顶端的SEH通过TEB(线程环境块)0字节偏移处的指针标识。
(4)当异常发生时,操作系统会中断程序,并首先从TEB的0字节偏移处取出距离栈顶最近的SEH,使用异常处理函数句柄所指向的代码来处理异常。
(5)当离事故现场最近的异常处理函数运行失败时,将顺着SEH链表依次尝试其他的异常处理函数。
(6)如果程序安装的所有异常处理函数都不能处理,系统将采用默认的异常处理函数。通常这个函数会弹出一个对话框,然后强制关闭程序。
3.SEH攻击
思路:将异常处理函数的指针,替换成shellcode的指针。SafeSEH和SEHOP,微软的新seh,无法被利用了。
(1)SEH存放在栈内,我们可以精心制造出溢出数据来把SEH的异常处理的函数地址替换为shellcode的起始地址。
(2)溢出后错误的栈帧或堆块数据往往会触发异常,我们能查到哪些能触发异常的片段。
(3)当Windows开始处理溢出后的异常时会调用shellcode,它会把shellcode当作异常函数来处理异常。
4.SEH代码事例
1 |
|
(1)函数test中存在典型的栈溢出漏洞。
(2)_try{}会在test的函数栈帧中安装一个SEH结构。
(3)_try中的除0操作会产生一个异常
(4)当strcpy操作没有产生溢出时,除0操作的异常将最终被MyExceptionHandler函数处理。
(5)当strcpy操作产生溢出,并精确地将栈帧中的SEH异常处理句柄修改为shellcode的入口地址时,操作系统将会错误地使用shellcode去处理除0异常,代码植入成功。
(6)此外,异常处理机制会检测进程是否处于调试状态。如果直接用调试器加载程序,异常处理会进入调试状态下的处理流程。因此我们在代码中加入断点_asm int 3,让进程中断,然后用调试器attach的方法进行调试。
(考过选择题,没有SEH啊)5.Windows内存安全机制概述:*GS编译、DEP、Heap cookie、Safe Unlink、ASLR
动态内存安全
动态内存管理概述
1.动态内存管理函数(知道每个函数作用)
(1)C标准定义的内存分配函数:calloc()、malloc()、realloc()。
(2)使用free()函数释放内存,C++使用new表达式分配内存,使用delete表达式释放内存。
(3)malloc(size_t size):分配size个字节,并返回一个指向分配的内存的指针。分配的内存未被初始化为一个已知值。
(4)free(void * p):释放由p指向的内存空间,这个p必须是先前通过调用malloc(),calloc(),或者realloc()返回的。如果free(p)此前已经被调用过,将会导致未定义行为;如果p是空指针,则不执行任何操作。
(5)realloc(void p, size_t size):将p所指向的内存块的大小改为size个字节。新大小和旧大小中较小的值那部分内存所包含的内容不变。新分配的内存未做初始化。如果p是空指针,则该调用等价于malloc(size)。如果size等于0,则该调用*等价于free(p)。如果p不是空指针,则其必须是早先调用malloc(),calloc(),或者realloc()所返回的结果。
(6)calloc(size_t nmemb, size_t size):为数组分配内存,该数组共有nmemb个元素,每个元素的大小为size个字节,并返回一个指向所分配的内存的指针。所分配的内存的内容全部被设置为0。
2.内存管理器
(1)既管理已分配的内存,也管理已释放的内存。作为客户进程的一部分运行。
(2)内存分配的不同算法
①连续匹配方法。查询匹配的第一个空闲块(从当前开始)
②最先匹配。从内存开始位置寻找第一个空闲块。
③最佳匹配。选择大小满足要求(>=),且最小的块。(恰好)
④最优匹配:对空闲块取样,选取第一个比样本更合适的块,返回最优结婚策略。
⑤最差匹配:挑最大的空闲块
⑥伙伴系统方法:以前的方法可能导致片段化;伙伴系统只分配$2^i$大小的块;倘若需要m大小的块,分配$2^{[\log_b m]}+1$大小;当块返回时,尝试和它相邻的同样大小的块合并。
⑦隔离。保持单独的大小一致的块的列表。一直都是2、4、6的大小的块。
(3)返回已释放的块到池中,合并临近空闲块为更大的块,有时使用压缩的预留块,把所有块移到一起。
常见的内存管理错误
(考过)初始化错误、未检查返回值、引用已释放内存、对同一块内存释放多次、不正确配对的内存管理函数(new对delete才对)、未能区分标量和数组、分配函数使用不当(比如malloc(0))。
1.初始化错误
(1)程序员假设malloc()把分配的内存的所有位初始化为零
(2)初始化大的内存块可能会降低性能并且不总是必要的:程序员必须用memset()或通过调用calloc()初始化内存,它们都将内存清零
考试练习题(解答题,看看):该段代码存在什么错误?如何修复?
(1)int *y = malloc(n * sizeof(int)):分配的内存包含随机值,y[i]没有被初始化为0。需要调用calloc()将内存清零。
(2)没有检查内存分配是否成功,函数返回局部变量的指针。
1 | /* return y = Ax */ |
2.未检查返回值
(1)内存是有限的资源,它可能会被耗尽。
(2)内存分配函数报告调用者状态:VirtualAlloc()返回NULL、(MFC)new表达式抛出CMemoryException、HeapAlloc()可能返回NULL或者产生结构化异常。应用程序应该:*决定什么时候错误发生,以合适方式处理异常。
(3)如果不能分配请求的空间,那么malloc()函数返回一个空指针。在不能分配内存时,有个一致的恢复计划是需要的。
(4)PhkMalloc:提供了一个X选项,在启用主选项的情况下,当分配失败时,内存分配器会向标准错误输出设备打印一段诊断信息并调用abort(),而不是返回错误状态值。
(5)如果没有内存可分配的话,malloc返回空指针。C++中的new表达式抛出bad_alloc异常:使用new,将分配封装在try块中。
- 检查malloc返回值
1 | int *i_ptr; |
- new表达式异常处理
1 | try { |
- 不合语法!
1 | int *pn = new int; |
- 使用像malloc的新方法的nothrow变种
1 | int *pn = new(nothrow) int; |
3.引用已释放内存
(1)几乎总能成功,因为释放的内存是被内存管理器回收的
(2)不可能导致运行时错误:因为内存由内存管理器所有。
(3)已释放的内存在读操作之前可被分配:读操作读取的数值不正确,写操作损坏其他变量。
(4)已释放内存能被内存管理器使用:写操作能损坏内存管理器元数据,很难诊断运行时错误,漏洞利用的基础。
4.多次释放内存
(1)经常是剪切和粘贴错误
1 | x = malloc(n * sizeof(int)); |
(2)数据结构包含指向同一项的链接
(3)错误处理:结果是内存块被释放,但在正常处理过程中再次被释放。一般来说内存泄露比双重释放更安全。
5.不正确配对的内存管理函数
(1)总是使用:new←→delete、malloc←→free
(2)有时不恰当的配对在某些平台仍能工作,但是代码是不可移植的。
6.未能区分标量和数组:C++对于标量和数组有不同的表达式。new←→delete标量、new[]←→delete[]数组。
7.分配函数的不当使用
(1)malloc(0),即分配0字节:能导致内存管理错误,C运行时库能返回空指针和伪地址。最安全和便捷的解决方案是确保没有零长度分配。
(2)使用alloca()
①功能:在调用者的栈中分配内存,在调用alloca()的函数返回时自动释放该内存
②问题:通常实现为内联函数,不返回空的错误,分配空间时超出栈边界。
dlmalloc
1.dlmalloc管理内存块:空闲、分配。内存块要么被分配给进程,要么空闲。
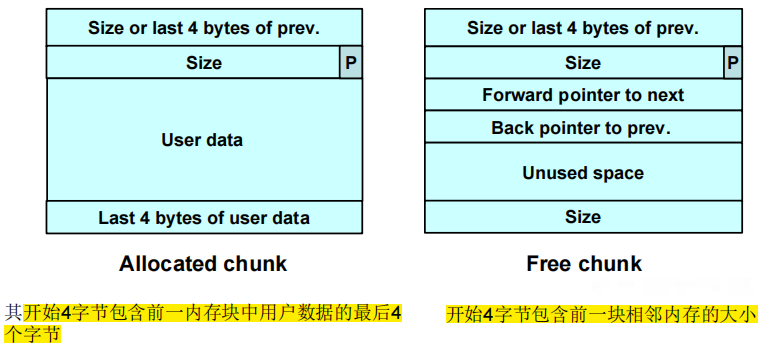
2.Dlmalloc空闲块管理
(1)以双链表形式组织起来,包含指向下一块的前向指针和指向上一块的后向指针,最后4字节存有该块的大小。
(2)已分配块和空闲块都使用一个PREV_INUSE位区分:块大小总是偶数,PREV_INUSE位被存储于块大小的低位中。
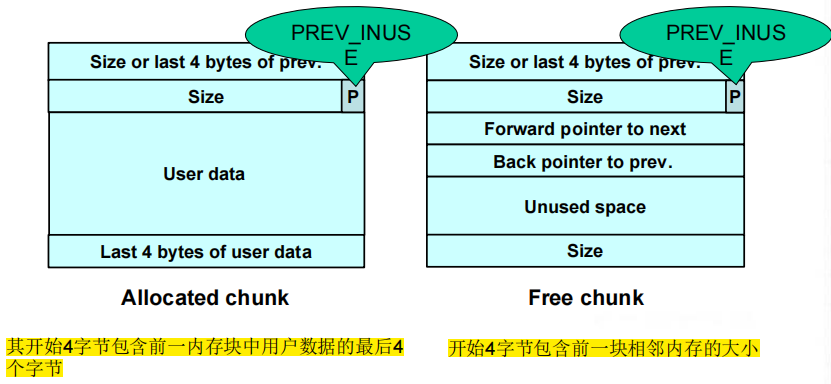
(3)空闲块被组织成筐,由头索引,筐中的块大约同样大小,还有一个包含最近释放的块的筐做为缓存。
(4)空闲块合并时:相邻空闲块,合并
3.解链技术:Unlink宏(记一下步骤)
1 |
|
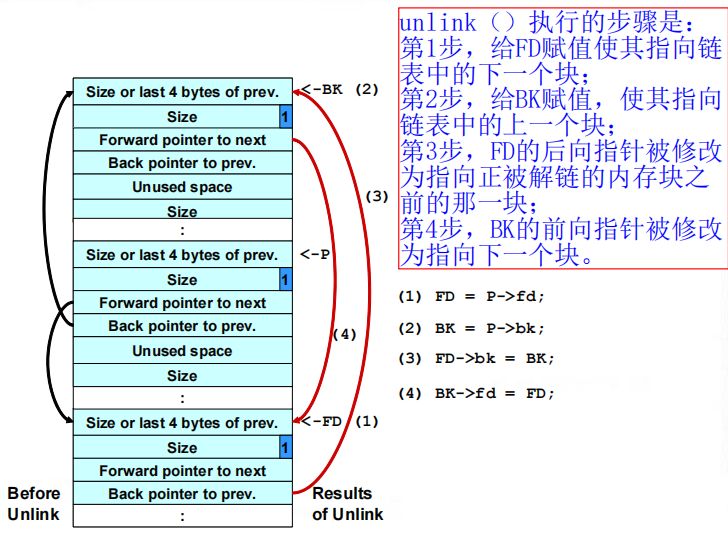
unlink是一种攻击技术。利用缓冲区溢出来操作内存块的边界标志。用来攻击dlmalloc,覆盖先前的PREV_INUSE字段。可以任意写4字节数据。
考试练习题:
1 |
|
- 对于strcpy(first, argv[1]):程序接受单个字符串参数并将其复制到first中,无界strcpy()操作容易引发缓冲区溢出。
- 程序调用free()释放第一块内存。
- 如果第二块内存处于待分配状态(即空闲),free()操作将会试图将其与第一块合并。
- 为了判断第二块内存是否处于空闲状态,free()会检查第3块的PREV_INUSE标志位。
- 参数会覆写第二块内存中表示上一块内存大小的域、块大小值以及前向指针和后向指针,从而也就修改了free()操作的行为。
- 第二块内存的大小域的值被修改为-4,因此当free()需要确定第三块内存的位置时,也就是说将第二块内存的起始位置加上其大小时会导致将其起始位置减4。Doug Lea的malloc此时会错误地认为下一连续内存块自第二块内存前面4字节起。
- 这个恶意参数也会使dlmalloc所找到的PREV_INUSE标志位为空,从而dlmalloc误以为第二块内存是未分配的,导致free()调用unlink()宏来合并这两块内存。

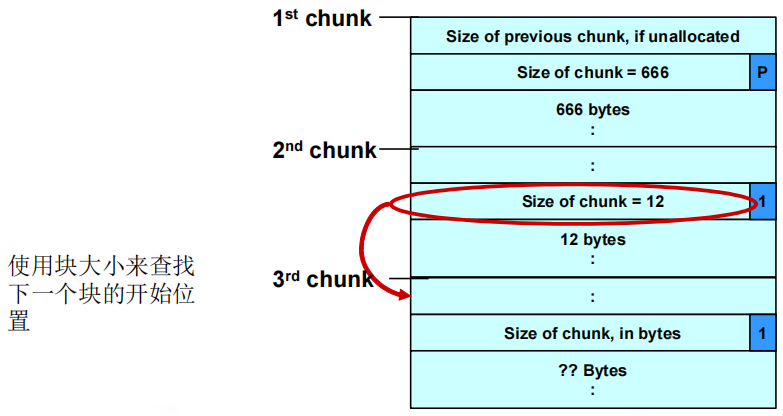
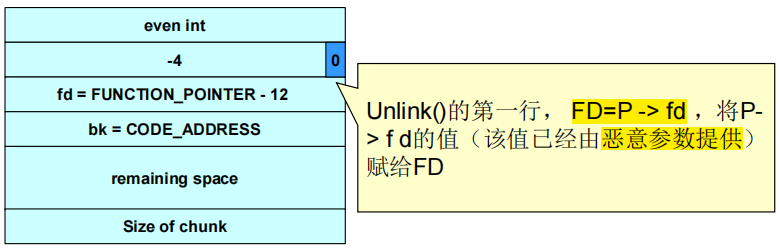
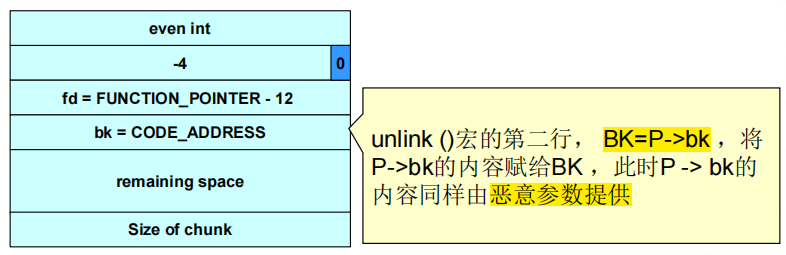
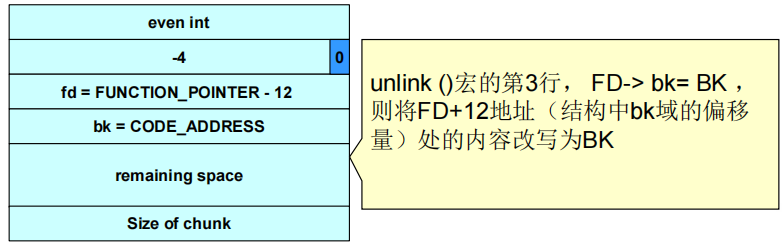
(3)unlink()宏将攻击者提供的4个字节的数据写到同样是由攻击者指定的4个字节的地址处。
①一旦攻击者可以在任意地址处写入4字节数据,利用该漏洞程序本身的权限执行任意代码就变得简单多了。
②攻击者可能会提供栈中指令指针的地址,然后利用unlink()宏将该地址覆写为恶意代码的地址。
③将漏洞程序调用的函数的地址替换为恶意代码的地址。
④攻击者可以检查程序的可执行映像,找到free()函数的调用跳槽(jump slot)地址:address-12处的值包含在恶意参数中,因此unlink()宏会将free()库函数调用地址覆写为shellcode的地址。每当程序调用free()时都会转而执行shellcode。
(4)对堆缓冲区溢出的利用并不是特别困难的事情:该利用方式最困难之处在于精确地确定第一块内存的大小,以便计算出需要覆写的第二块内存的地址。攻击者可以从dlmalloc中复制request2size(req,nb)宏的代码到其利用代码中,然后使用这个宏计算出块的大小。
4.Frontlink技术
(1)和unlink相比较,frontlink技术更难以应用但也很危险:当一块内存被释放时,它必须被正确地链接进双链表中。在dlmalloc的某些版本中,此项操作是由frontlink()代码段完成的。我们的目标是在攻击者指定的地址写入攻击者指定的数据。
(2)实现:攻击者指定一个内存块的地址而不是shellcode的地址,在这个内存块的起始4个字节中放入可执行代码。通过往上一内存块的最后4个字节中写入指令实现的。
(3)练习题
攻击者提供恶意实参:包含一段shellcode,该shellcode的最后4个字节就是跳转到shellcode其他部分的跳转指令,并且这4个字节是first块的最后4个字节。为了确保该条件能够满足,被攻击的内存块必须是8的整数倍减去4个字节长。
C语言代码
1 |
|
- strcpy(first, argv[2]):将argv[2]复制到first块
- free(fifth):当fifth内存块被释放时,它被放入一个筐中(1508)
- strcpy(fourth, argv[1]):其直接前驱内存块fourth被精心设计的数据所填满(argv[1]),因此这里就发生了溢出。并且fifth的前向指针指向了一个假的内存块。这个假的内存块的后向指针的位置包含有一个函数指针的地址(假的内存+12,也就是后向):一个合适的函数指针是存储于程序.dtors区中的第一个析构函数的地址。攻击者可以通过检查可执行映像而获得这个地址,一般就是前面指针讲到过的。
- free(second):当second块被释放时,程序使frontlink()代码段将其插入到与fifth块相同的筐中。
- return(0):对return(0)的调用,本来应该导致程序的析构函数被调用,而现在实际调用的却是shellcode。
frontlink代码片段
1 | BK = bin; |
- while (FD != BK && S < chunksize(FD)) :second比fifth内存块小,frontlink()代码段中的while循环得以执行。
- FD = FD->fd:fifth块的前向指针被存储到FD中,这是一个假地址,他的后向,也就是+12的地方是类似.dtors函数位置。
- BK = FD->bk:找到的FD是假地址(比如.dtors中指针的前12个字节),而此处循环的BK原本应该就是第5块的,但是这里做了精心处理,变成了包含函数地址(此处是.dtors相关)的一个地址了。此处用second来覆盖.dtors地址,而second为first覆盖,指向的是first中的shellcode。前向的后向指向second,这样就替换了假地址的后向,也就是改变了.dtors的值。
- FD->bk = BK->fd = P:现在BK包含有函数指针的地址(指针值减8),函数指针被second块的地址所覆写。
- 当frontlink()执行完毕后,second块的前向指针和后向指针都分别指向函数指针。
6.双重释放漏洞(考了n次)
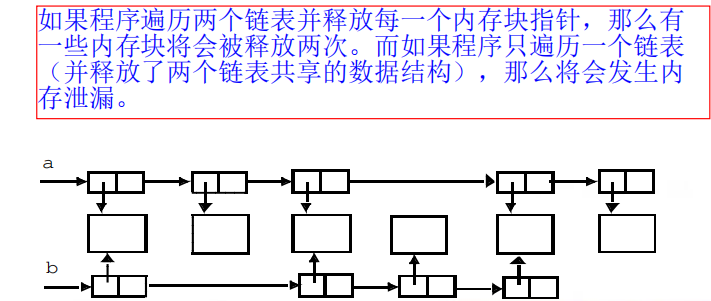
(1)这种类型的漏洞是由于对同一块内存释放两次所造成的(在这两次释放之间没有对内存进行重新分配,被释放的内存块相邻的内存块必须已分配)
(2)要成功地利用双重释放漏洞,有两个条件必须满足:被释放的内存块必须在内存中独立存在、该内存所被放入的筐(bin)必须为空。
(3)一个空的筐和一个已分配的内存块:空的筐仅仅包含头,筐和内存块之间没有任何联系。
(4)块被释放后,它被放入筐中:在调用frontlink后,筐的前向和后向指针指向已释放的块
(5)对内存块的第二次释放毁坏了筐结构:frontlink
(6)该漏洞可被利用的进一步说明:技术是困难的,已释放的内存没有立即放入筐中,而是被缓存。双重释放块可能和其他块合并。
练习题:
1 | static char *GOT_LOCATION = (char *)0x0804c98c; |
- first = (void *)malloc(256):利用方式的目标是分配的first块
- second = (void *)malloc(256);third = (void )malloc(256);fourth = (void )malloc(256):对second和fourth块的分配,**可以阻止third块与first块合并。
- free(first):当first块在初次释放时,会被放入缓存筐而不是普通筐。
- free(third):释放third块将first块移到普通筐。
- fifth = (void )malloc(128):分配fifth块会造成内存从third块处分开,一部分分配了,另一部分*还在筐中。
- free(first):内存已经配置成功,因此对first的第二次释放构成双重释放漏洞。
- sixth = (void )malloc(256):分配sixth块时,malloc()返回的指针*与first所指向的内存块相同。
- *((void *)(sixth+0))=(void *)(GOT_LOCATION-12):在被释放后,**写入到first块。*
- *((void *)(sixth+4))=(void *)shellcode_location:strcpy()函数的GOT地址(减去1)以及shellcode位置**被复制到这块内存(first块)。*
- seventh = (void )malloc(256):相同的内存块被再一次分配给seventh块。当内存块被分配后,unlink()宏将shellcode的地址*复制到全局偏移表中strcpy的地址处。
- strcpy(fifth, “something”):调用strcpy()时,程序的控制权被转移到shellcode中。shellcode跳过最初的12个字节,因为这部分内存的一些已经被unlink()宏所覆写。
双重释放漏洞很难利用,但是在现实世界中已经被成功利用过。写入到已释放内存也是安全缺陷。

RTL堆
1.Windows内存管理
(1)虚拟内存API:32位地址,4KB页,用户地址空间分区域(保护方式、类型以及每页的基分配方式)
(2)堆内存API:允许用户建立多个动态堆,每一个进程都有一个默认堆。
2.RTL堆
(1)使用虚拟内存API,实现了更高级的局部、全局和CRT内存函数。
(2)内存管理API的错误使用可能导致软件漏洞。需要理解的RTL数据结构:进程环境块、空闲链表、look-aside链表、内存块的结构
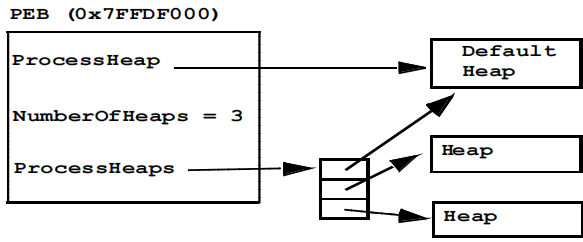
①进程环境块:PEB维护有每一个进程的全局变量,PEB被每一个进程的线程环境块(TEB)所引用,TEB则被fs寄存器所引用。
PEB给出堆数据结构的信息:堆的最大数量、堆的实际数量、默认堆的位置、一个指向包含所有堆位置的数组的指针。
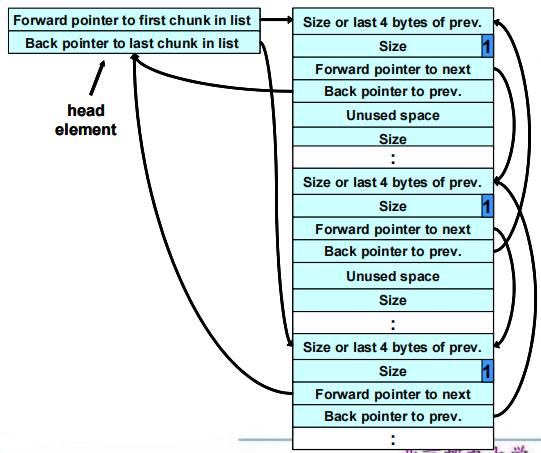
②空闲链表:有128个双向链表的数组。位于堆起始(也就是调用HeapCreate()返回的地址)偏移0x178处,这个链表被RtlHeap用来跟踪空闲内存块。
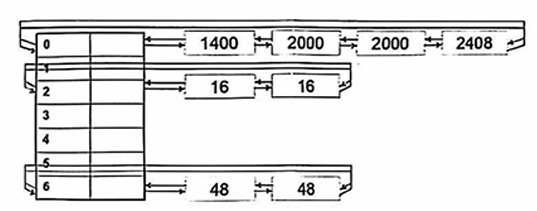
Freelist[]是一个LIST_ENTRY结构的数组,每一个LIST_ENTRY表示一个双链表的头部。LIST_ENTRY结构定义于winnt.b中,由一个前向链接(flink)和一个后向链接(blink)组成。
以下图考试练习题有:
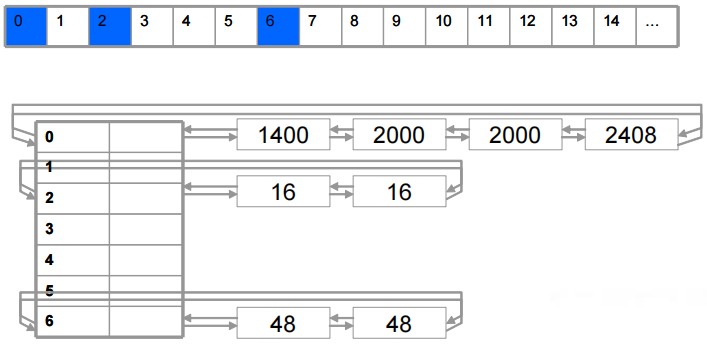
- 链表中的空闲块从最小到最大排序,该数据结构所代表的堆包含有8个空闲块:其中有2个空闲块是16字节长,由存储于Freelist[2]中的链表维护,另外的两个48字节长的空闲块由Freelist[6]所维护。
- 块大小等于表格行索引乘以8个字节(Freelist[0]除外)。
- 块大小与空闲链表在数组中的位置之间的关系均得到了维护。最后的4个空闲块大小分别为1400、2000、2000和2408字节,它们都比1024大,因此都由Freelist[0]维护,并且按大小升序排列。当创建一个新堆时,空闲链表被初始化为空。当链表为空时,前向和后向链接都指向链表头。
- 页中未作为第一个内存块的一部分而分配出去的内存,以及那些没有被用作堆控制结构的内存,就被加入空闲列表。对于较小的分配(指的是小于1472字节),大于1024的被加入到Freelist[0]中。假设空间足够的话,后续的分配都从这个空闲块中进行。
③后备缓存链表
- 在堆分配时创建,用于加速对小块内存(这里指的是小于1016字节)的分配操作。后备缓存链表一开始被初始化为空链表,然后随着内存被释放而增长。后备缓存链表会先于空闲链表被检查。

- 后备缓存链表中的空闲块的数量会被自动调整:根据特定大小内存块的分配频率。一个特定大小的内存被分配得越频繁,在相应链表中存储该大小的内存块的数量就越多,对后备缓存链表的使用使得小块内存的分配速度加快。
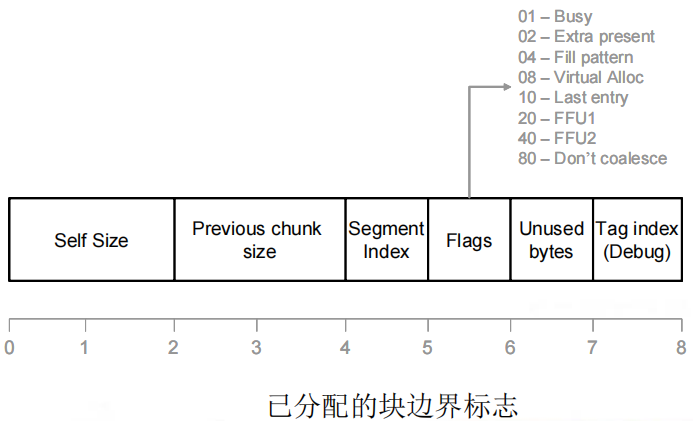
3.边界标志
(1)调用HeapAlloc()或malloc()所返回的。这个结构位于HeapAlloc()所返回的地址之前,偏移量为8个字节。包含:自身大小、前一块大小、busy标志位、传统的部分。
(2)当块被释放时:边界标志仍然存在,空闲内存包含下一块和上一块地址,busy标志位被清空。
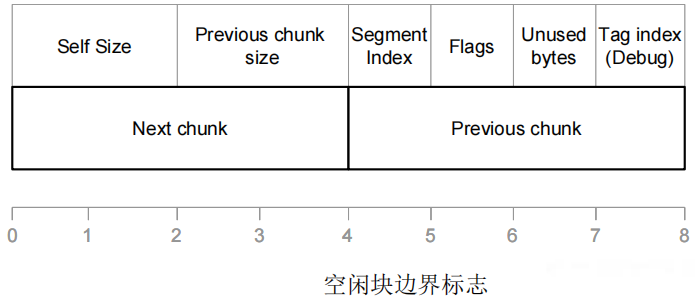
4.基于堆的缓冲区溢出攻击:通常需要改写双链表结构中的前向和后向指针。正常的堆处理过程覆写地址,从而修改程序的执行流程。
练习题有此代码题:发生缓冲区溢出时,h2的前向指针被覆写为0012f5b8,后向指针被覆写为00409040。
1 | unsigned char shellcode[] = "\x90\x90\x90\x90"; |
(1)第6行调用Heapcreate()创建了一个新的堆,初始大小为0x1000,最大大小0x10000。建立一个新堆简化了利用,因为我们知道堆中的确切内容。第7~9行分配了3个不同大小的内存块。这些内存块的空间是连续的,因此时没有合适大小的空闲块可用。
(2)第10行释放h2导致在已分配内在中打开了一个缺口。这个内存块被加入空闲链表中,意味着其起始8个字节被用指向空闲链表头部的前向和后向指针改写,且busy标志位也被清空。从h1开始,内存按照如下方式排列:h1块、空闲块和h3块。
(3)在本示例利用代码第11行的缓冲区溢出发生处,我们没有做任何掩饰性的工作。在这个memcpy()操作中,malArg的起始16个字节覆写了用户数据区域。接下来的8个字节覆写了空闲块的这个标志。在本例中,利用代码只是保留了现有的信息,因此接下来的正常操作未受影响。malArg接下来的8个字节覆盖了指向下一个和上一个块的指针。下一个块的地址被将被覆写的地址所覆盖(在本例中是栈中的一个返回地址)。上一个块的地址被shellcode的地址所覆写。
(4)现在第12行调用HeapAlloc()所需要的舞台都已搭建完毕,调用发生后,程序的返回地址将被shellcode的地址覆盖。之所以如此,是因为对HeapAlloc()的这次调用所请求的字节数与上一个空闲块大小相同。结果,RtlHeap从包含受害块的空闲链表中取得了内存块。当空闲块从空闲双链表中移出时,返回地址就被改写成了shellcode的地址。
(5)当mem()函数在第17行返回时,程序的控制权就转移给shellcode。
5.更容易的方法:通过覆写异常处理器地址获取控制、引发异常
练习题:
1 | int mem(char *buf) { |
第一次调用HeapAlloc()后的堆的组织形式:
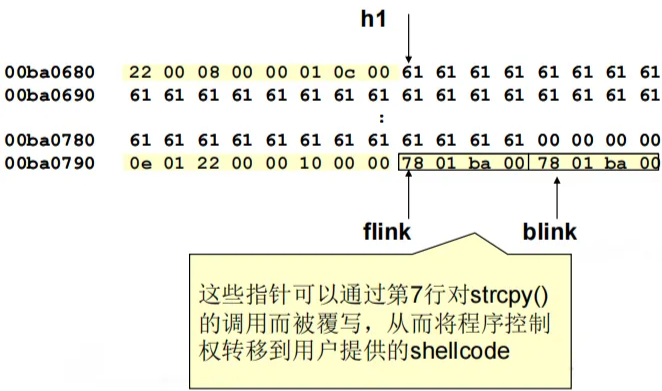
- h1 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 260):分配了一个单独的内存块堆,包括:段头为h1所分配的内存段尾。变量h1指向0x00ba0688,这也是用户内存的起始地址。
- strcpy((char *)h1, buf):堆溢出:覆写段尾,包括LIST_Entry结构指针。很可能在下一个对RtlHeap的调用时被引用。这会触发一个异常。
- 第一次调用HeapAlloc()后,指向Freelist[0]的前向指针(flink)和后向指针(blink)的地址分别是0x00ba0798和0x00ba079c,这些指针可以通过对strcpy()的调用被覆写。
6.RTL Heap
练习题:
1 | char buffer[1000]=""; |
- strcat(buffer, “\x73\x68\x68\x08”):前向指针被控制权将要转移到的地址所取代。
- strcat(buffer, “\x4c\x04\x5d\x7c”):(这两行代码,10和11行)改写了尾随空闲块的前向和后向指针。后向指针则被将要被覆写的内存地址所取代。
- strat(buffer, “\x33\xC0\x50\x68\x63\x61\x6C\x63\x54\x5B\x50\x53\xB9”):偏移量会覆写尾随的空闲块的后向指针,因此缓冲区控制转移到用户提供的地址,而不是未处理的异常处理器。
- 用来覆盖前向指针的地址就是shellcode的地址,因为RtlHeap接下来会改写shellcode的起始4个字节,对于攻击者而言,更容易的办法应该是采用一个跳板。跳板允许在事先不知道shellcode的绝对地址的情况下将程序的控制权转移到shellcode处。跳板可以通过检查程序的映像或动态链接库进行定位,也可以通过加载库并搜索内存来动态地定位。
- RTL堆可能存在漏洞:写入已释放内存、双重释放、Look-Aside表
考试练习题:
1 | // RTLHeap:写入已释放内存 |
- 代码中所包含的RTL堆漏洞是写入已释放的内存。
- h2 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 32):对HeapAlloc()的调用使得HeapFree()的地址被shellcode的地址所覆盖。
- 当释放h1时,它被放入一个空闲块大小为32字节的空闲列表中。在空闲列表中可使用的内存块的第一个双字保存有指向链表中下一个内存块的前向指针,第二个双字保存有后向指针。前向指针被待改写的地址所取代,后向指针则被shellcode的地址所覆盖。
练习题:
1 | // RTLHeap: 双重释放 |
释放h2之后:
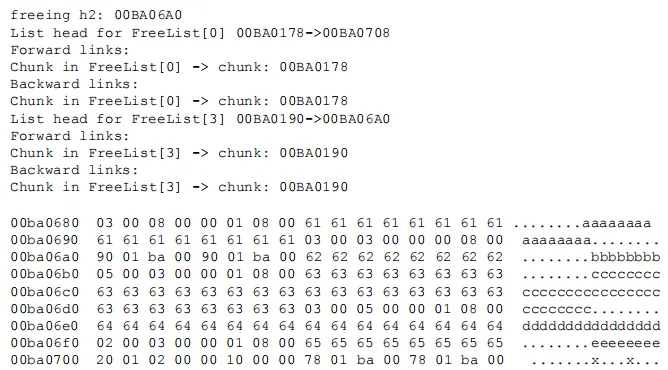
- FreeList[0]在0x00BA0708处包含有一个空闲块。
- FreeList[3]包含有另一个空闲块,这个空闲块就是h2。h1由“aaa…a”填充等。
释放h3之后:
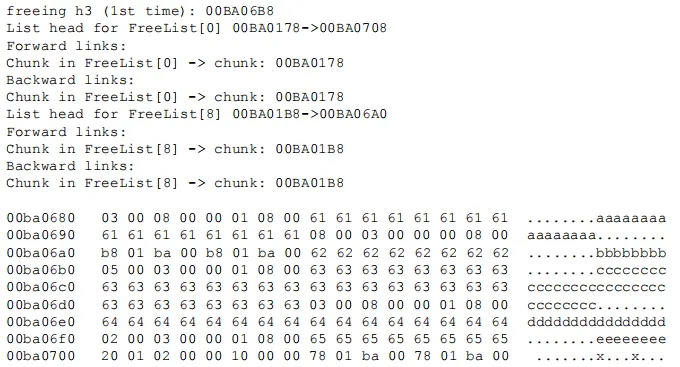
- 此时h2和h3合并,在FreeList[8]新的空闲块h3的用户区域的起始8个字节并不包含指针,但h2中的指针已经被更新。h2中的指针被更新为指向FreeList[8]。
第二次释放h3之后:
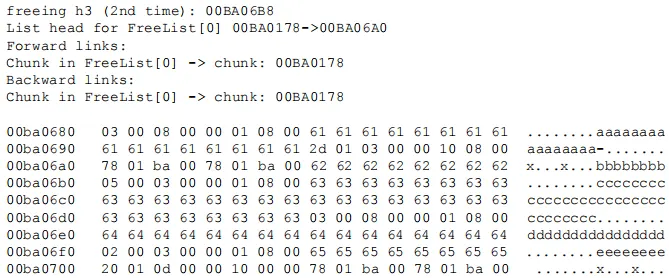
- h3释放第二次之后:空闲块完全消失了,FreeList[0]指向0x00BA06A0: 一个2KB大小的空闲块。
- 已分配的h4 and h5正好位于这块虚假的未分配的区域。利用:覆写指向FreeList[0]的前向和后向指针。位于0x00BA06A0,当前不可访问。
- 漏洞利用代码分配另外的64字节空间,将8字节的头部以及前向和后向指针数据写入0x00ba06e0,也就是h4所指向的内存块,能被覆写。
缓解策略
1.PhkMalloc
(1)被设计成可以在一个虚拟内存系统中高效运作,这样就能执行更强的检查,在不解引用指针的前提下判定传递给free()或realloc()的指针是否有效。
(2)不能检测是否传递了一个错误(但有效)的指针,但它可以检测所有不是由malloc()或realloc()返回的值。
(3)检测一个指针是已分配的还是空闲的,因此它可以检测所有的双重释放错误。对于未授权进程而言,这些错误都被当作警告看待。启用“A”或“abort”选项则会导致这些警告被当作错误看待,一个错误就表示一个终点,会导致调用abort()
(4)加入了“J(unk)”和“Z(ero)”选项,从而可以检测出更多的内存管理缺陷。J(unk)选项会在已分配的区域内填充Oxd0,Z(ero)选项也给分配的区域填充垃圾数据,当用户请求的精确长度为0时则不进行操作。
2.随机化
(1)malloc()调用返回的地址在很大程度上是可预测的
(2)程序返回的内存块地址随机化,可以使对基于堆的漏洞利用变得更加困难
3.哨位页
(1)都是未映射的,被放置到已分配内存(一个页或更大)之间的空间
(2)当攻击者在利用缓冲区溢出哨位页时,程序会引发段故障。OpenBSD, Electric Fence, Application Verifier都实现了哨位页。哨位页有着很大的开销。
4.著名的漏洞:缓冲区溢出漏洞、微软数据访问组件、CVS服务器双重释放漏洞、Kerberos 5中的漏洞
整数安全
整数数据类型
1.整数安全例子
1 | int main(int argc, char *argv[]) { |
2.整数表示方法:原码、反码、补码。对整数表示法而言,需要考虑的问题主要就是负数的表示。
(1)原码值的表示方法
利用最高位表示数值的符号:0正、1负。余下的所有低位表示值的大小。如果最高位未置位,表示+41,如果最高位被置位,则表示-41。
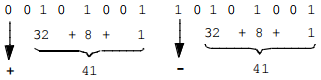
(2)反码表示法
由于实现原码表示法所需的电路过于复杂,因此人们后来采用反码表示法取而代之。将一个整数值的每一位取反,就得到于其对应的负数。
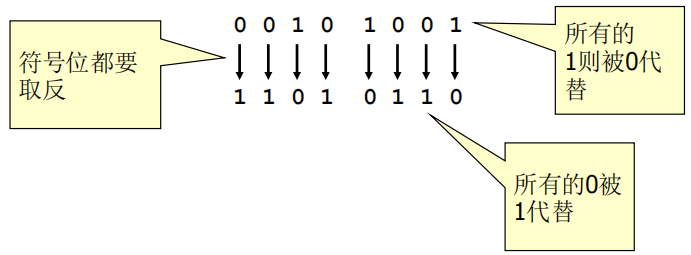
练习:整数10101001用反码表示为01010110
(3)补码表示法
补码表示法的负数是在反码表示法的结果末位加1而得。补码表示法对0只有+0一种表示。最高位仍然是符号位。正数的补码表示法则与原码表示法相同。
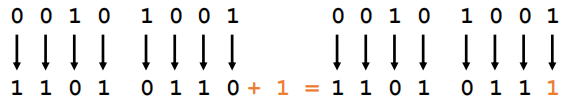
练习:整数00101000用补码表示为00101000
3.带符号和无符号类型
(1)C和C++中的整数分为带符号和无符号两种,每一种带符号类型都有对应的无符号类型。
(2)带符号整数:带符号整型用来表示正值和负值。在一个使用补码表示法的计算机上,带符号整数的取值范围是**$(-2^{n-1})$~$(2^{n-1})-1$。反码和原码最小值:$(-2^{n-1})+1$**
(3)无符号整数:取值范围是0~$2^n-1$。任一种带符号整型都有对应的无符号整型。
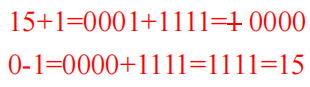
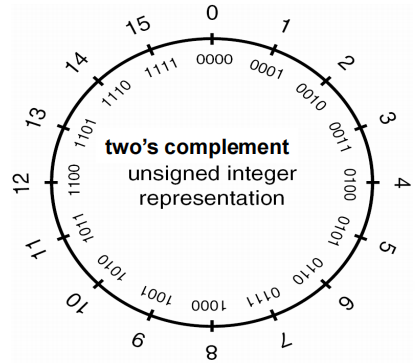
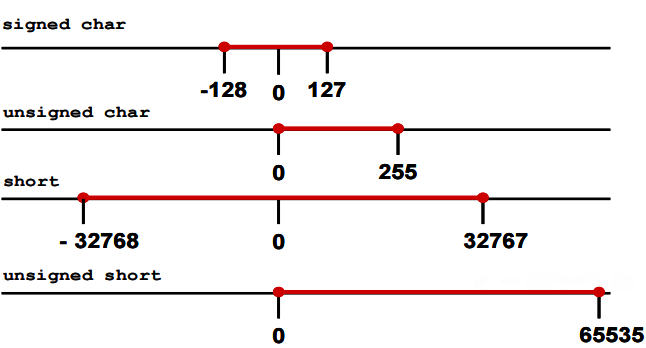
4.整数取值范围:一个整数类型的最大值和最小值取决于该类型的表示法、是否带符号、分配的内存位数大小。
整数的转换
1.整型转换
(1)在C和C++中,类型转换既可能作为转型操作的结果显式发生,也可能因为某个操作的需要而隐式发生。
(2)整型转换可能会导致数据丢失或错误的表示。隐式转换是C语言可以对混合数据类型执行操作能力的结果。
(3)整型提升、整型转换级别、普通算术转换。
2.整型提升
(1)在比int小的整型进行操作(算术运算、函数参数、函数返回值)时,它们会被提升。
(2)如果原始类型的所有值都可以用int表示,较小的类型会被转换成-个int,否则被转换成-个unsigned int。
(3)整型提升被作为普通算术转换的一个组成部分:某些自变量表达式、一元的+-和~操作符、移位操作
(4)例子:由于整型提升,因此这里c1和c2都要被提升到int类型的大小:char c1, c2; c1 = c1 + c2; 然后两个int类型的数据相加,求和结果被截断以适应char类型的大小。整型提升主要是为了防止运算过程中中间结果发生溢出而导致算术错误。
3.隐式转换:两个不同类型变量进行算术运算,或不同类型变量间的赋值。
考试题:问你输出
1 | char cresult, c1, c2, c3; |
4.整数转换级别规则
(1)没有任何两种不同的带符号整型具有相同的级别,即使它们的(内存)表示法相同。
(2)低精度的带符号整型的级别比高精度的带符号整型类型的级别低。
(3)long long int类型的级别比long int高,long int的级别比int高,int的级别比short int高,short int的级别比signed char高。
(4)无符号整型的级别与对应的带符号整型的级别相同。
本质:每一个bit都不会变化,只是表示的意义可能变得不同,比如说符号位的变化;或者,高位可能被舍弃。
5.从无符号整型转换
(1)从较小的无符号整型转换到较大的无符号整型总是安全的,通常通过对其值进行零扩展而完成
(2)当一个较大的无符号整型被转换到一个较小的无符号整型的时候:较大的值将会被戳断、低位数据被保留
(3)当无符号整型转换到其对应的带符号整型的时候:位模式(即所有的位数据)将会被保留,因此没有数据会因此丢失;最高位数据变成了符号位。如果该符号位被置位,该值的符号和大小都会发生改变。
注意一下什么时候数据曲解
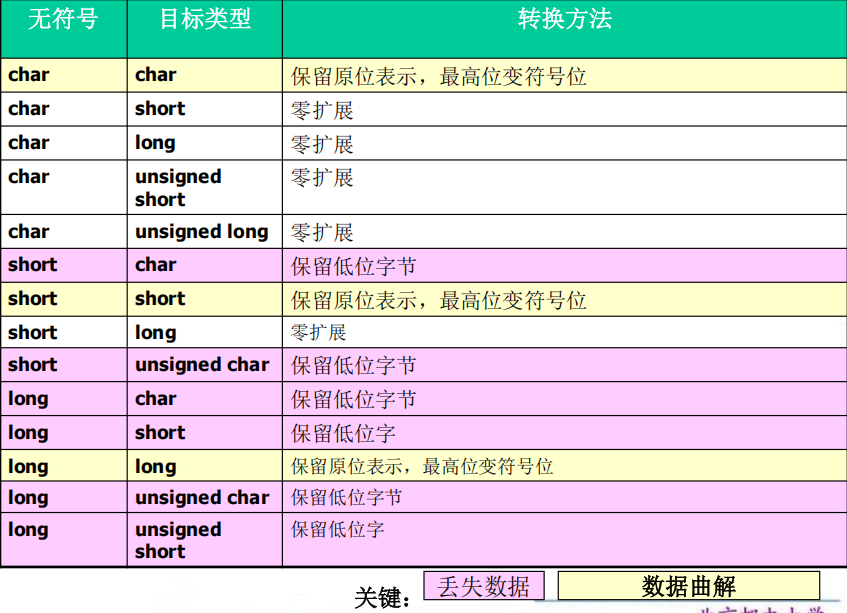
6.带符号整型转换
(1)当一个非负的带符号整数被转换为一个相同大小或更大的无符号整型的时候:值不会发生变化,带符号整数需作符号扩展。
(2)当一个带符号整数被转换为一个较短的带符号整数的时候,则是通过截断高位完成的。
(3)当带符号整数转换到无符号整数:其位模式被保留,故不会有数据的丢失。高位失去了符号位的功能。
(4)如果带符号整型的值非负,那它的值不会发生改变。
(5)如果其值是负数,得到的无符号结果将被求值为一个非常大的带符号整数。
注意一下什么时候数据曲解,相同时候
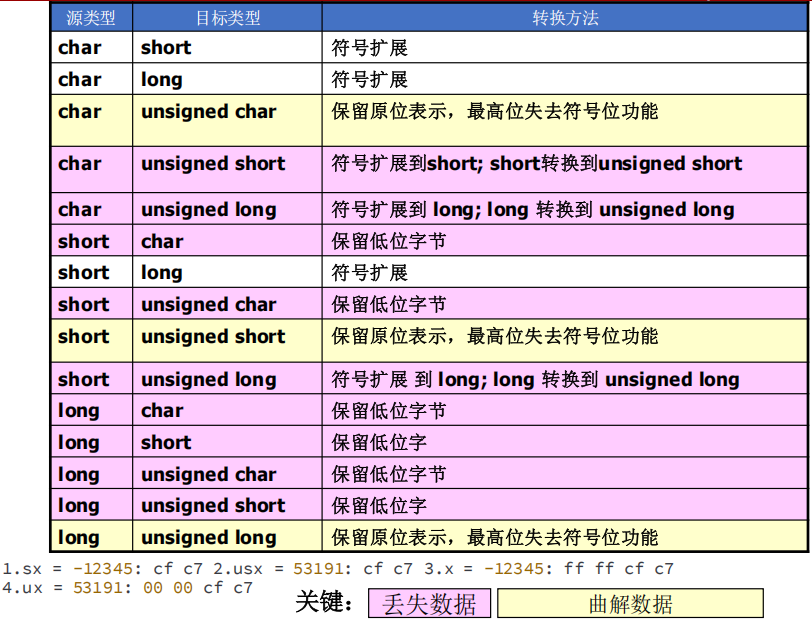
1 | unsigned int l = ULONG_MAX; |
7.带符号或无符号字符
(1)char类型既可以是带符号的,也可以是无符号。
(2)当一个符号位被置位的signed char类型的数据被当作整型保存时,其结果就是一个负数。
(3)当处理值可能会大于127(0x7F)的字符数据时,对于涉及的字符缓冲区、指针及转型,最好用unsigned char代替char或signed char。
8.普通算术转换
(1)如果两个操作数具有同样的类型,则不需要进一步的转换。
(2)如果两个操作数拥有同样的整型(带符号或无符号),具有较低整数转换级别的类型的操作数会被转换到拥有较高级别的操作数的类型。
(3)如果具有无符号整型操作数的级别大于或等于另一个操作数类型的级别,则带符号整型操作数将被转换为无符号整型操作数的类型。
(4)如果带符号整型操作数类型能够表示无符号整型操作数类型的所有可能值,则无符号整型操作数将被转换为带符号整型操作数的类型。否则,两个操作数都被转换为与带符号整型操作数类型相对应的无符号整型。
整数错误情形
整型操作溢出、符号错误、截断错误会导致非预期的结果。
9.整数溢出:int_max++会变成int_min
(1)当一个整数被增加超过其最大值或被减小小于其最小值时即会发生整数溢出
(2)带符号和无符号的数都有可能发生溢出:带符号溢出发生于对符号位执行进位时;无符号溢出则发生于当底层表示不再能够表示-个值时。
有相似的练习题,问输出:
1 | int i; |
10.截断错误:大整型到小整型,高位丢失,只保留低位。
(1)截断错误发生于将一个较大整型的数转换到较小的整型,该数的原值超出较小类型的表示范围。
(2)原值的低位被保留下来而高位则被丢弃。
考试练习题:
1 | char cresult, c1, c2, c3; |
- c1加c2超过了signed char(+127)的最大值。当该值赋给一个太小的数据类型的时候,而无法表示结果值的时候。会发生截断错误。(即cresult1发生整数截断)在操作前,把比int小的整型提升为int或unsigned int。
- cresult2不会。
11.符号错误:即无符号数和有符号数之间的转换,由于高位的标志位代表意义不同导致的。
(1)从无符号整型转换到带符号整型。
①相同大小:位模式保留不变,最高位变成符号位。
②更大:进行符号扩展,然后才执行转换。
③更小:保留低位。
(2)如果无符号整数的最高位:没被设置,值不变;被设置,变成负值。
(3)带符号整型转换到无符号整型。
①相同大小:位模式保留不变,最高位变成符号位。
②更大:进行符号扩展,然后才执行转换。
③更小:保留低位。
(4)如果带符号整数的值:是非负的,值不变;负的,结果通常是一个很大的正值。
考试练习题:
1 | int i = -3; |
- 有足够的位来表示值,所以没有发生截断。但是补码表示法被解释为一个大的符号值,所以输出的u=65533,FFFD。
整数的操作
整数操作会导致错误和非预期的值。非预期的整数值可能会导致非预期的程序行为、安全漏洞。大部分整数操作会导致异常条件。
1.整数的重要使用场景:作为数组索引、在任何指针的算术运算中、作为一个对象的长度或大小、作为一个数组边界(例如一个循环计数器)、作为内存分配函数的参数、在对安全要求很关键的代码中。
2.异常情况
(1)不包含算术转换产生的错误
(2)整数错误能够被侦测,有符号溢出和无符号回绕都被描述为适当的先验条件测试和后验条件测试。
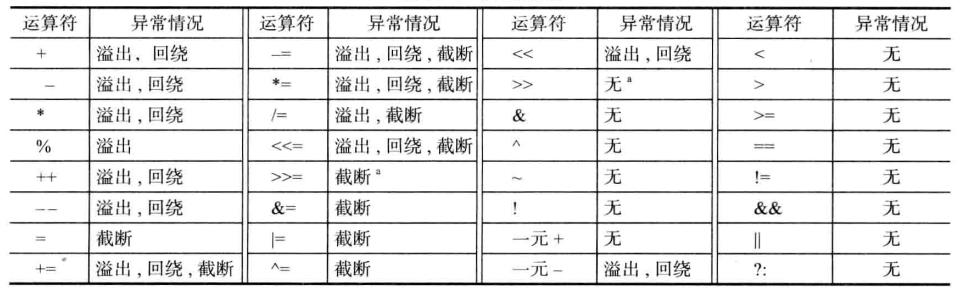
3.整数加法
(1)加法用来将两个算术操作数或者一个整数与一个指针相加。如果两个操作数都是算术类型,那么将会对它们执行普通算术转换。如果结果整型占用的位数不足以表示其结果,那么就会导致溢出。
(2)IA-32加法指令:add destination,source。将第一操作数(目的)与第二操作数相加,并将结果存放到目的操作数。目的操作数可以是一个寄存器或者内存位置。源操作数可以是一个立即数、寄存器或者内存位置。侦测和报告带符号和无符号的整数溢出条件。
(3)add ax,bx:将16位寄存器bx和16位寄存器ax相加,并将结果存储到寄存器ax中。
(4)加法指令在标志寄存器中设置标志:一个用于指示带符号算术溢出的溢出标志、一个用于指示无符号算术溢出的进位标志。
(5)解释标志:在机器水平上带符号和无符号的整数是没有区别的。整数溢出和进位标志必须要根据实际情况来解。
(6)加法:带符号/无符号的char
①当把两个signed char相加的时候,它们的值会发生符号扩展。
1 | sc1 + sc2 |
②当把两个unsigned char相加的时候,它们的值会发生零扩展来避免改变大小。
1 | uc1 + uc2 |
(7)加法:带符号/无符号的int
把两个unsigned int相加,为signed int的值生成相同的代码
1 | ui1 + ui2 |
(8)加法:带符号的long long int
1 | sll1 + sll2 |
(9)无符号整数溢出检测
①进位标志意味着无符号算术溢出
②无符号整数溢出通过使用下列方法检测:jc指令(如果有进位标志,则转跳)、jnc指令(如果没有进位标志,则转跳)
③这些跳转指令放在下列条件后:做32位运算时,放在指令add之后;做64位运算时,则放在adc之后。
(10)带符号整数溢出检测
①进位标志意味着带符号算术溢出
②带符号整数溢出通过使用下列方法检测:jo指令(如果有溢出,则转跳)、jno指令(如果没有溢出,则转跳)
③这些跳转指令放在下列条件后:做32位运算肘,放在指令add之后;做64位运算肘,则放在adc之后。
(11)先验条件
①先检查可能会否溢出!带符号整数的相加可能会导致整数溢出,如果加法操作的左操作数(LHS)和右操作数(RHS)的和大于UINT_MAX(对于int相加而言)或大于UL LONG_MAX(对于unsigned long long相加而言)的话。
②先验条件例子
当A和B是无符号的,并且满足下列条件时,会发生整数溢出:A + B > UINT_MAX
整数溢出防范检测代码:A > UINT_MAX – B
当A和B是long long int,并且满足下列条件时,会发生整数溢出:A + B > ULLONG_MAX
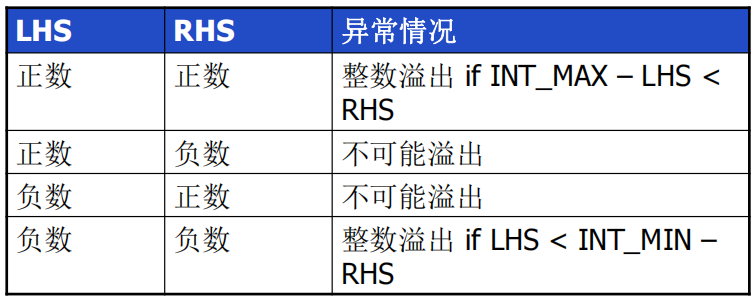
(12)Int类型的带符号整数相加(练习题有一道选择题)
(13)后验条件:先执行加法,然后对结果进行评估。
例如: 令sum = lhs + rhs。如果lhs非负且sum < rhs**,表明发生了溢出;如果**lhs**为负且**sum > rhs,表明发生了溢出。所有其他的情况则表明加注操作成功完成而无溢出。对于无符号整数来说,如果sum比任意一个操作数小,就表明发生了溢出。
4.整数减法
(1)IA-32指令集包含sub(减法)、sbb(带借位减法)。sub和sbb指令可以对溢出和进位标志置位,以表示带符号或无符号结果的溢出。
(2)sub指令:sub指令从第一个操作数(目的操作数)中减去第二个操作数(源操作数),并将结果存储在目的操作数中。目的操作数可以是一个寄存器、内存位置;源操作数可以是一个立即数、寄存器、内存位置。
(3)sbb指令:指令sbb通常被用在多字节或多字减法场合。sbb指令将源操作数(第二个操作数)和进位标志相加,并从目的操作数(第-操作数)中减去刚才所得的结果。减法操作的结果被存储在目的操作数中。进位标志表示上一个减法操作中是否有借位出现。
(4)带符号long long整型Sub
1 | sll1 - sll2 |
(5)先验条件
①要测试无符号整数减能是否溢出,只需检验是否LHS < RHS。
②对于具有相同符号的精符号整散,不会发生异常情况
③对于混合符号的带符号整数情形,应用下列规则:如果LHS为负,而RHS为正,对signed int类型检查LHS < INT_MIN **+** RHS;如果LHS非负,且RHS为负,检查LHS > INT_MAX + RHS
④例如,0-INT_NIN会导致溢出情况,因为该操作的结果比能表示的最大值还要大1。
(6)后验条件
①如果要测试带符号整数的溢出,设difference = LHS - RHS,并应用如下规则:如果RHS非负,并且difference > LHS,则发生了溢出;如果RHS为负,并且difference < LHS,则发生了溢出;其他所有情况,没有溢出发生。
②对于无符号整数而言,如果difference > LHS,则发生溢出。
5.整数乘法
(1)乘法操作容易引起溢出错误,因为当进行乘法运算时,即使是较小的操作数也可能导致给定的整数类型溢出。其中一个解决方案是,为积分配两倍于两个操作数中类型较大者的大小的存储空间。
(2)乘法指令:IA-32指令集包含有一个mul(无符号乘法)指令、imul(带符号乘法)指令。
mul指令:用于将第一个操作数(目的操作数)和第二个操作数(源操作数)相乘,并将结果存储在目的操作数中
1 | if (OperandSize == 8) { |
(3)进位标志和整数溢出标志:如果需要高位来表示两个操作数的积,则进位标志和溢出标志都被置位;如果不需要高位(也就是说它们全为0),那么进位标志和溢出标志都被消除。
①带符号和无符号字符乘法(Visual C++)
练习题:考填空
1 | sc_product = sc1 * sc2; |
②带符号和无符号字符乘法(g++)
不管char是否带符号,g++对char类型的整数都使用mul指令的字节形式。
1 | sc_product = sc1 * sc2; |
g++对单字长度的整型,则采用imul指令,不管该类型是否带符号。
1 | si_product = si1 * si2; |
(4)先验条件:为了防止无符号整数相乘时发生溢出,可以检验A * B > MAX_INT,也就是A > MAX_INT/B,但是除法的开销更大。
(5)后验条件
①后验条件同样可以用来检测乘法溢出,不过由于结果需要“两倍于较大操作数的大小”的位数进行表示,因此与加法相比这种情形要复杂一些。
②将两个操作数放到下一个更大的数据类型上,然后相乘。
对于无符号整数:检查下一个大整数的高阶位,如果被设置了,抛出错误。
对带符号整数:如果结果的高半部分及低半部分的符号位全为0或1,则没有发生整数溢出。
③对于16位带符号整数,可以通过这种方式简化对溢出的检测:将LHS和RHS两个操作数都转型成32位值,并将乘积结果存储到32位的目的域中。如果结果积右移16位和右移15位所得结果不一致,则说明发生了溢出。
④对于正的结果,这种方法可以检测结果值是否溢出到低16位中的符号位,对于负的结果,这种方法可以检测结果值是否溢出到高半部分的位中。
6.整数除法
(1)如果32位或64位的带符号整数的MIN_INT值除以-1,那么将会发生溢出。在32位情况下,–2147483648/-1的结果应该等于2147483648。由于2147483648无法用带符号的32位整数表示,所以结果出错。**-2147483648/-1 = -2147483648。**如果参与除法操作的整数的符号和类型不同,那么也容易出问题。
(2)错误检测:IA-32指令集包含如下除法指令div,divpd,divps,divsd,divss,fdiv,fdivp,fidiv,idiv
①div指令:用源操作数(除数)除存储于ax、dx:ax或edx: eax寄存器中的(无符号)整数(被除数),并将结果存储于ax(ah:al)、dx:ax或edx:eax寄存器中。
②idiv指令:对(带符号)值执行同样的操作。
③Intel除法指令div和idiv没有设置整数溢出标志
④下列情况会产生除法错误:源操作数(除数)为0,对于目的寄存器而言结果商值太大。除法错误会导致一个中断标志向量0。错误报道时,处理器恢复错误指令开始执行时的机器状态。
(3)带符号整数除法
1 | mov eax, dword ptr [si_dividend] |
(4)无符号整数除法
1 | **ui_quotient = ui1_dividend / ui_divisor;** |
(5)先验条件:可以通过检查分子是否为整型的最小值以及检查分母是否为-1来防止整型除法溢出的发生。当然,只要确保除数不为0,就可以保证不发生除零错误。
整数的漏洞
漏洞:一系列允许违反显式或隐式的安全策略的情形。安全缺陷可能是由于硬件层的整数错误或者是跟整数有关的不完善逻辑所造成的。当这些安全缺陷与其他情形结合起来时,就可能会产生漏洞。
1.JPEG例子:基于在处理JPEG文件注释域时存在的实际漏洞
(1)JPEG文件的注释域中包含一个长为两个字节的长度域,后者用来指示注释域的长度(也包括该两个字节的长度域本身在内)
(2)为了确定注释字符串的单独长度(以便进行内存分配),函数会读取长度域的值并将其减2。
(3)后函数根据注释的长度加上用于表示终结null字符的1个字节所得的总长度来分配内存空间。
Integer整数溢出例子:
*考试原题(重点,考了n次):指出并分析下面程序的整数溢出问题
1 | void getComment(unsigned int len, char *src) { |
- 分配到0字节内存的调用可以成功执行,由于size被声明为unsigned int,当执行size=len-2时,如果len的值小于2,那么len-2的结果将是一个负数。由于size被声明为unsigned int,它不能表示负数,此时会发生整数溢出。例如,如果len为1,len-2结果为-1。在无符号整数的表示中,**-1会被转换为一个非常大的正数(具体值取决于size_t的位数)。**
- malloc(size+1)会分配一个非常大的内存块,这可能会导致内存分配失败,因为系统没有足够的连续内存来满足这个请求。memcpy(comment,src,size)会尝试将src中的数据复制到comment中,由于size是一个错误的大值,这可能会导致访问越界,破坏其他内存区域的数据,引发程序崩溃。
- getComment(1, “Comment”):当图像注释的长度域的数值为1时可能会产生溢出。当getComment的参数len=1时,可能发生段错误(缓冲区溢出/内存访问越界),此时size**=0xFFFFFFFF**。
2.内存分配例子
(1)整数溢出例子也会发生于内存分配calloc()时,当计算一块内存区域的大小并调用calloc()或其他内存分配函数来分配内存时可能会引起整数溢出
(2)可能会返回一个小于需求大小的缓存,从而可能会导致后面的缓冲区溢出
(3)以下代码片断可能会产生漏洞
C: p = calloc(sizeof(element_t), count);
C++: p = new ElementType[count];
(4)内存分配
①库函数calloc()接受两个参数:存储元素类型所需要的空间、元素的个数
②对于C++的new操作符的情形,则不需要显式指定元素类型大小
③为了计算所需内存的大小,使用元素个数乘以该元素类型所需的单位空间来计算
(5)整数溢出条件
①如果计算所得结果无法用带符号整数表示,那么,尽管分配程序看上去能够成功地执行,但实际上它只会分配非常小的内存空间。
②应用程序对分配的缓冲区的写操作可能会越界,从而导致基于堆的缓冲区溢出。
3.符号错误例子
考试题:
1 |
|
- 变量len在第3行被声明为带符号整型,这就决定了它在第5行被赋值时可能会得到一个负值。负值可以绕过第6行的检查,因为小于设定的缓冲区(BUFF_SIZE)长度。在第7行对memcpy()的调用中,这个带符号整数被视作一个size_t类型的无符号整数。这就导致了一个符号错误,因为负的长度值(len)被解释为一个很大的正整数,从而导致缓冲区溢出。
- 这个漏洞可以通过限制整数len为一个有效值来避免:
①加设一个更有效的范围校验以保证len的值在0到BUFF_SIZE之间(0<len<BUFF_SIZE)
②声明为无符号整型:消除在调用函数memcpy()时从带符号整型到无符号整型的转换、防止发生符号错误。
4.截断:漏洞执行
练习题:整数截断导致缓冲区溢出
1 | bool func(char *name, long cbBuf) { |
(1)cbBuf被临时保存在了一个unsigned short bufsize中。不论是GCC还是Visucal C++,在基于IA-32的编译器上,unsigned short的最大值都是65535。而同一平台上signed long的最大值是2147483647。任何值位于65535和2147483647之间的cbBuf在进行赋值时都会发生截断错误。
(2)当bufSize同时用于调用malloc()和memcpy()的时候,只会发生错误并不会产生漏洞。
(3)由于bufSize被用于分配缓冲区的大小,而cbBuf则是用来在调用函数memcpy()时指定大小,因此任何在1到2147418112(2147483647-65535)字节之间的buf值都会引起溢出。
(4)假设unsigned short的最大值为a,signed long的最大值是b。由于bufSize被用于分配缓冲区的大小,而cbBuf则是用来在调用函数memcpy()的指定大小,因此,任何在a+1到b字节之间的buf值都会引起溢出。
5.非异常的整数逻辑错误
(1)许多可利用的软件缺陷并不完全需要一个异常条件(比如整数溢出)。
(2)负数索引
(3)考试题:
1 | int *table = NULL; |
- 如果pos是负值,value将被写入缓冲区pos*4字节之前的位置
- 漏洞:对插入位置pos缺乏必要的范围检查,因此将会导致一个漏洞。因为pos开始时被声明为带符号整数,即传递到函数中的值可正可负。可以捕获下标越界的正值,但是负值却不会被捕获。
- 可以通过在判断pos>99之前同时加入pos<0的判断修复该漏洞。
6.其他C99整数类型
(1)下面的类型有特定的用处:
①ptrdiff_t为表示两指针相减的结果的带符号整型;size_t是表示sizeof操作符结果的无符号整型。
②wchar_t的取值范围可以表示所支持的现场(locales)中最大扩展字符集中的所有字符代码。
(2)介绍案例
考试题代码:指出存在问题
未检查argc是否≥3,直接访问argv[1]和argv[2]存在空指针风险。
未检查malloc返回值是否为NULL,可能导致对空指针写入数据而崩溃。
1 | int main(int argc, char *const *argv) { |
- 漏洞:攻击者可能会提供两个总长度无法用unsigned short整数total表示的字符串做参数strlen()函数返回一个size_t类型,一个IA-32上的unsigned long int。因此,lengths+1的和是一个unsigned long int。分配给unsigned short int total时值必须被截断。一旦长度的总和大于结果类型的表示范围,它将会被截模截断。
- 攻击者可能会提供两个总长度无法用unsigned short整数total表示的字符串做参数。这样,一旦长度的总和大于结果类型的表示范围,它将会被取模截断。举例来说,如果第一个参数的长度是65500个字符,第二个参数的长度是36个字符,那么它们的长度总和加1将是65537个字符。函数strlen()被定义成返回一个类型size_t的结果,通常就是一个unsigned long。由于65500和36都是unsigned long,三个值的和也必然是unsigned long。而将一个unsigned long赋值给一个unsigned short型的变量total,必然要进行降级操作。假设short是16位,则上述运算的结果是(65500+37)%65536=1。根据这个结果,函数malloc()能够成功地分配所需的字节(即1个),但是该分配为strcpy()和strcat()的执行创造了缓冲区溢出条件。
7.NetBSD例子
(1)NetBSD 1.4.2及之前的版本中都使用了以下形式的整数范围检查:**if(off>lensizeof(type-name)) goto error;**这里的off和len都是带符号整型。
(2)漏洞:sizeof操作符返回的是一个无符号整型(size_t),因此整数提升规则要求len-sizeof(类型名)。应该按照无符号整型计算,当len小于sizeof的返回值时:减法操作造成下溢并产生一个很大的正值,整数范围检查逻辑被绕过。
(3)利用:一种能够消除此类问题的替代形式的整数范围检查:if ((off+sizeof(type-name))>len) goto error;程序员仍然必须保证off的值在一个定义的范围之内,以确保加法操作不会导致溢出。
缓解策略
1.范围检查
(1)如果适当地运用类型范围检查,就够消除所有的整型漏洞。(第一条防线)诸如Pascal或者Ada这些语言,允许对任何标量类型应用范困限制,以形成子类型。
(2)以Ada为例,允许使用range关键字来声明对派生类型的范围约束type day is new INTEGER range 1..31;范围约束会被语言运行时强制执行,C和C++在强制类型安全性方面并不擅长。
练习题:
1 |
|
- 当len ≥ BUFF_SIZE时,可以绕过范围检测导致缓冲区溢出错误,可以通过使用strncpy函数避免。
2.范围检查解释
(1)仅仅将len声明为无符号整数并不足以完成范围约束,因为它只能约束从0到MAX_INT的范围。检查上下界,确保不会将越界的值传递给memcpy()。同时使用隐式和显式检查看上去有些累赘,但是我们推荐这种健康的偏执式的编程实践。
(2)所有外部输入的数据都要进行上下界检查:应该通过接口来强制执行对它们的限制。任何能够限制过大或过小输入的措施,都有助于防止溢出和其他类型范围错误。
(3)排版约定:区分代码中的常量和变量,区分受外部影响的变量和拥有良好定义范围的局部变量。
3.强类型:提供更好的类型检查的方式之一是提供更好的类型定义。将一个变量声明为无符号的类型就能够保证该变量不会包含负值。这种解决方案不能阻止溢出。
4.抽象数据类型:解决方案之一是创建一个包含私有数据成员waterTemperature的抽象类型,用户不能直接访问该数据成员。这些方法中必须提供类型安全机制,以保证waterTemperature的值在有效范围之内。如果正确地做到了这一点,就不可能再发生整型范围错误了。
5.Visual C++编译器检查
(1)当一个整数值被赋给较小的整型时,Visual C++ NET 2003编译器会生成一个警告。
(2)在警告级别1,如果类型为_int64的值被赋值给unsigned int类型。在警告级别3和4,如果一个整型被转换给一个较小的整型将会生成“可能会丢失数据”警告。在警告级别4下,以下例子中的赋值就会生成一个C4244警告。
1 | int main() { |
6.Visual C++运行时检查
(1)当一个整数值被赋给较小的整型时,Visual C++ NET 2003编译器会生成一个警告。
(2)/RTCc提供了与C4244警告类似的功能,以报告当一个整数被赋值给较小的整型时所导致的数据丢失。
(3)Visual C++中还包含一个runtime_checks pragma,用于禁用或启用/RTC设置,但它并不包括用于捕获其他运行时错误(例如溢出)的标志。
7.加带符号的整数
1 | Wtype __addvsi3 (Wtype a, Wtype b) { |
8.安全的整数操作
(1)整数操作可能会导致溢出和数据丢失。防止整数漏洞的第一条防线就是进行范围检查:显式、隐式-通过使用强类型达。很难保证多个输入变量不被恶意用户操纵,从而导致程序中的某些操作出错。
(2)另一种可选的或者说是辅助的方式是将每一个操作保护起来。这属于一种劳动密集型的方式,实现起来代价很大。让输入可能被不确定来源所影响的所有整数操作都使用一个安全整数库。
9.无符号的加函数
1 | in bool UAdd(size_t a, size_t b, size_t *r) { |
1 | int main(int argc, char *const *argv) { |
10.SafeInt类
(1)在执行操作之前对操作数的值进行测试,以决定是否会导致错误。
由于这个类被声明为模板类,因此可以用于任何整数类型。重截了几乎每一个有关的操作符。({}下标索引操作符除外)
1 | int main(int argc, char *const *argv) { |
(2)整数安全解决方案对比:与Howard方法相比,Safelnt库有好几个优点。
①比依赖于汇编语言指令实现务全算术操作的Howard方法移植性更好
②更好的可用性:算术操作符可以用于常规的内联表达式、Safelnt使用C++异常处理机制代替C风格的返回代码检查。
③更好的性能表现(对于启用优化编译选项的应用程序而言)
12.整数安全库使用
(1)什么时候使用:让输入可能被不确定来源所影响的所有整数操作都使用一个安全整数,比如结构大小、分配的结构的个数
1 | void* CreateStructs(int StructSize, int HowMany) { |
(2)什么时候不使用:不需要使用安全整数进行操作。被紧密控制的循环、变量不受外部影响。
1 | void foo(){ |
格式化输出
格式化输出相关知识
格式化输出的简介
(1)格式化输出函数参数由一个格式字符串和可变数目的参数构成
①格式化字符串提供了一组可以由格式化输出函数解释执行的指令
②用户可以通过控制格式字符串的内容来控制格式化输出函数的执行
(2)变参函数在C语言中实现的局限性导致格式化输出函数的使用中容易产生漏洞。
1 |
|
变参函数
1.ANSI C标准参数
(1)在ANSI C的标准参数方式(也称为stdargs)中,变参函数是通过使用一个部分参数列表后跟一个省略号进行声明的。若要调用一个变参函数,仅需指定该次调用中所需数目的参数即可:average(3,5,8,-1);
(2)使用stdargs实现average()函数
练习题:
1 | int average(int first, ...) { |
(3)变参函数average()接受一个独立的定参,其后跟着一个变参列表。对该变参列表中的参数不会执行任何类型检查。省略号之前通常有一个或多个定参,而省略号则必须出现在参数列表的最后。
(4)ANSI C为了实现变参函数所提供的宏,va_start(), va_arg()和va_end()的定义。这些定义在头文件stdarg.h中的宏,全部作用于va_list数据类型以及使用va_list类型声明的参数列表之上。
2.可变参数宏定义示例
1 |
|
(1)宏va_arg()需要一个已初始化的va_list和下一个参数的类型。这个宏可以根据这些信息返回下一个参数的值,并且相应地递增参数指针。
(2)average()第8行调用va_arg()宏,通过循环,获取第2个直至最后一个参数。最后,在函数返回之前,调用va_end()来执行清理工作。
(3)参数列表的终止条件是函数的实现者和使用者之间的一个契约。在函数average()的实现中,变参列表的终止是由一个值为-1的参数所指定的。
(4)如果程序员在调用该函数时忘记传入这个特殊的参数,则函数将继续处理下一个参数,直到遇到-1或者发生异常为止。
3.采用字符指针定义的va_list类型
(1)(练习题代码)在这些系统中调用函数average(3,5,8,-1)时,参数被如何按序安排在栈上。
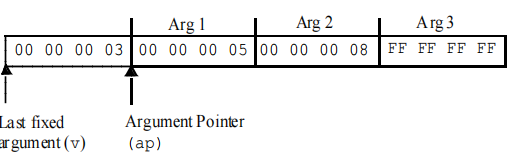
(2)在用va_start()初始化字符指针后,字符指针指向最后一个定参之后的那个参数。va_start()宏将该参数的(类型)大小加上最后一个定参的地址。当va_start()返回时,va_list将指向第一个可选参数的地址。
(3)并不是所有系统都把va_list类型定义成字符指针。一些系统将其定义成指针数组,另外一些系统则把它放在寄存器中作为参数传递。当参数在寄存器中传递时,va_start()可能不得不为它们分配内存空间。宏va_end()就被用来释放分配的内存空间。
7.使用varargs实现的average()函数
1 | int average(va_alist) va_dcl { |
格式化输出函数
1.格式化输出函数
(1)fprintf()按照格式字符串的内容将输出写入流中。流、格式字符串和变参列表一起作为参数提供给函数。
(2)printf()等同于fprintf(),除了前者假定输出流为stdout外。
(3)sprintf()等同于fprintf(),但是输出不是写入流而是写入数组中。
(4)snprintf()等同于sprintf(),但是它指定了可写入字符的最大值n。超出部分会被舍弃,并且字符末尾会加上空字符。
(5)这些函数受到格式化字符串限制。当参数过多时,直接省略;参数过少时,结果未定义(会访问栈中原内容当作参数)。
2.相同的函数:vfprintf()、fprintf();vprintf()、printf();vsprintf()、sprintf();vsnprintf()、snprintf()。当参数列表是在运行时决定时,这些函数非常有用。
3.格式字符串
(1)格式字符串是由普通字符(包括%)和转换规范构成的字符序列。
(2)普通字符被原封不动地复制到输出流中。
(3)转换规范根据与实参对应的转换指示符对其进行转换,然后将结果写入输出流中。
(4)转换规范通常以%开始按照从左向右的顺序解释。
(5)当参数过多时,多余的将被忽略。而当参数不足时,则结果是未定义的。
(6)一个转换规范组成:
可选域:标志、宽度、精度以及长度修饰符
必需域:转换指示符,按照下面的格式
%[flags] [width] [.precision] [{length modifier}] conversion-specifier.
例如%-10.8ld:-是标志位,10代表宽度,8代表精度,l是长度修饰符,d是转换指示符。这个转换规范将一个long int型的参数按照十进制格式打印,在一个最小宽度为10个字符的域中保持最少8位左对齐。最简单的转换规范仅仅包含一个%和一个转换指示符(例如%s)。
4.宽度
(1)宽度是一个用来指定输出字符的最小个数的十进制非负整数。如果输出的字符个数比指定的宽度小,就用空白字符补足。
(2)如果指定的宽度较小也不会引起输出域的截断。如果转换的结果比域宽大,则域会被扩展以容纳转换结果。
(3)如果使用星号()来指定宽度,则宽度将由参数列表中的一个int型的值提供。在参数列表中,宽度参数必须置于*被格式化的值之前。
5.精度
(1)精度是用来指示打印字符个数、小数位数或者有效数字个数的非负十进制整数。
(2)精度域可能会引起输出的截断或浮点值的舍入。
(3)如果精度域是一个星号(*),那么它的值就由参数列表中的一个int参数提供。
(4)在参数列表中,精度参数必须置于被格式化的值之前。
对格式化输出函数的漏洞利用
当使用的格式字符串(或部分字符串)是由用户或其他非信任来源提供的时候,就有可能出现格式字符串漏洞。当格式化输出例程对一个数据结构进行越界写时就可能会导致缓冲区溢出。
1.缓冲区溢出:向字符数组中写入数据的格式化输出函数,会假定存在任意长度的缓冲区,从而导致它们易于造成缓冲区溢出。
考试练习题:
缓冲区溢出漏洞,发生于将%s替换成用户提供的字符串user(可能是恶意数据)时。
1 | char buffer[512]; |
因使用sprintf()所导致的缓冲区溢出漏洞,该漏洞发生于将转换指示符%s替换成用户提供的字符串。任何长度大于495字节的字符串都会导致越界写(512字节-16个字符字节-1个空字节)。
2.可伸展的缓冲区
练习题:
1 | char outbuf[512]; |
- sprintf(buffer,”ERR Wrong command: %.400s”,user):sprintf()调用并不会被直接利用,因为转换指示符%.400s限制了仅能写入400字节。
- sprintf(outbuf, buffer):同样的调用可被用于间接地攻击第4行中的sprintf()调用。例如用户通过使用下述值:%497d\x3c\xd3\xff\xbf
,在第3行调用的sprintf()直接将该字符串插入缓冲区。然后这个缓冲区数组将被作为格式字符串参数传递给在第4行被第二次调用的sprintf()。
(1)格式规范**%497d**指示函数sprintf()从栈中读出一个假的参数并向缓冲区中写入497个字符。
(2)包括格式字符串中的普通字符在内,现在写入的字符总数已经超过了outbuf的长度4个字节。
(3)用户输入可被操纵用于覆写返回地址,也就是拿恶意格式字符串参数中提供的利用代码的地址(0xbfffd33c)去覆盖该地址。
(4)在当前函数退出时,控制权将以与栈粉碎攻击相同的方式转移给利用代码。
(5)这个例子中的编程缺陷是由于在第4行不恰当地调用了sprintf()函数来实现字符串的复制功能,其实这里应该使用strcpy()或strncpy()。如果在第4行使用strcpy()来代替sprintf(),就能够消除这个漏洞。
3.输出流:将结果输出到流而不是输出到文件中的格式化输出函数(例如printf())也可能会导致格式字符串漏洞。
int func(char *user){printf(user);}
如果用户能够部分或者全部控制用户参数,那这个程序就会被利用从而导致程序崩溃、查看栈内容、查看内存内容或覆写内存。
4.使程序崩溃
(1)格式字符串漏洞通常是在程序崩溃的时候才被发现。Windows中,读取一个未映射的地址会崩溃;Unix中,存取无效指针会崩溃。
(2)(多次考)当用printf(“%s%s%s%s%s%s%s%s%s%s%s%s”)格式字符串调用格式化输出函数时,就会触发无效指针存取或未映射的地址读取。转换指示符**%s显示执行栈上相应参数所指定的地址的内存。由于在这个例子中没有提供字符串参数,因此printf()可以读取栈中任意内存位置,直到格式字符串耗尽或者遇到一个无效指针或未映射地址为止。**
5.查看栈内容:攻击者还可以利用格式化输出函数来检查内存的内容。
(1)反汇编printf()调用:
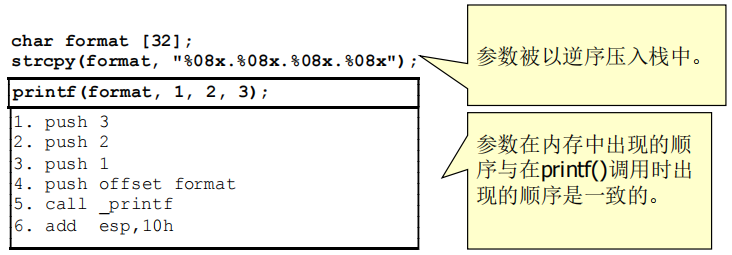
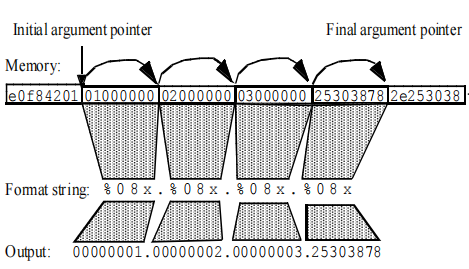
(2)过程:
①format字符串0xe0f84201的地址出现在内存中的位置恰好位于参数值1、2、3之前。
②紧邻参数之后的内存中包含有调用函数的自动变量,后者包括format字符数组0x2e253038的内容。
③本例中的格式字符%08x.%08x.%08x.%08指示函数printf()从栈中取回4个参数并将它们以8位十六进制数的形式显示出来。随着每一个参数被相应的格式规范所耗用,参数指针的值也根据参数的长度不断递增。
④格式字符串中的每一个别%08x都会从参数指针指定的位置读入一个被解释为int型的值。通过每一个格式字符串输出的这些值被显示在相应格式字符串下面。第四个“整数”包含格式字符串%08x的ASCII码的前四个字节。
(3)包括printf()在内的格式化输出函数使用一个内部变量来标志下一个参数的位置。栈的内容或栈指针并没有被修改,因此执行将按预期继续进行下去,直到控制权返回给调用程序。格式化输出函数将以这种形式持续显示内存中的其他内容,直到在格式字符串中遇到一个空字节。
(4)在显示完当前执行函数的剩余自动变量之后,printf()将显示当前执行函数的栈帧(包括当前执行函数的返回地址和参数)。由于printf()在内存中是按顺序“移动”的,所以它将会显示调用函数的同样的信息。一个函数调用一个函数,以此类推,直至整个栈。
(5)使用这个技术,有可能重建大部分的栈内存。攻击者可以使用这些数据来决定程序的偏移量或其他信息,从而进一步利用该漏洞或其他漏洞。
6.查看内存内容
(1)转换指示符%s显示参数指针所指定的地址的内存,将它作为一个ASCII字符串处理,直至遇到一个空字符。如果攻击者能够通过操纵这个参数指针来引用一个特定的地址,那么转换指示符%s将会输出该位置的内存内容。参数指针可以使用转换指示符%x进行前向移动。
(2)它所能移动的距离仅受格式字符串的大小所限制。攻击者就能够在调用函数的自动变量中插入一个地址。如果格式字符串被存储为一个自动变量,那么地址就能被插入在字符串的开始部分。攻击者可以按照下面的格式创建一个格式字符串来查看指定地址的内存:address advance-argptr %s
(3)查看某个具体位置的内存
考试练习题:
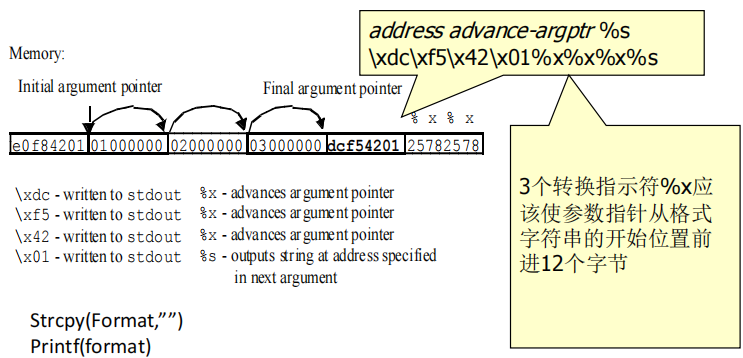
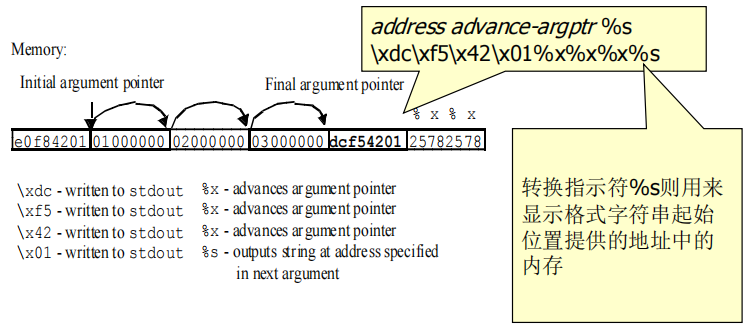
- 攻击者可以使用转换指示符%s显示参数指针所指定的地址的内存,将它作为一个ASCII字符串处理,直至遇到一个空字符。参数指针可以使用转换指示符%x进行前向移动,它所能移动的距离仅受格式字符串的大小所限制。
- 当攻击者提供的格式字符串为\xdc\xf5\x42\x01%x%x%x%s,printf()将显示从0x0142f5dc开始的内存直到遇到字节\0结束。3个转换指示符%x应该使参数指针从格式字符串的开始位置前进12个字节。
- 这个内存空间可以通过对函数printf()的调用之间的地址步进而被映射。查看任意地址的内存的能力有助于攻击者开发其他更具破坏性的利用,在受害计算机上执行任意的代码就是一个例子。
7.覆写内存
(1)格式化输出函数之所以具有特别的危险性是因为大多数程序员还没有意识到其破坏力。在那些整型值和地址具有同样大小平台上,向任意地址写入整型值的能力可被用于在受害系统上执行任意的代码。最初转换指示符**%n是用来帮助排列格式化输出字符串的。它将字符数目成功地输出到以参数的形式提供的整数地址中。**
(2)例如,在执行下面的代码片断后:int i;printf(“hello%n\n”, (int *)&i);变量i被赋值为5,因为在遇到转换指示符%n之前一共写入了5个字符(hello)。通过使用转换指示符%n ,攻击者可以向指定地址中写入一个整数值。为了利用这个安缺陷,攻击者需要向任意一个地址中写入-个任意值。
(3)调用:printf(“\xdc\xf5\x42\x01%08x.%08x.%08x%n”);将代表输出字符个数的整数值写入地址0x0142f5dc中。写入的值28。等于8字符宽的十六进制域(乘以3)的值加上4个地址字节的值。攻击者用某些shellcode的地址来覆写地址。
(4)如果攻击者能够控制格式字符串,那么他就能通过使用具有具体的宽度或精度的转换规范来控制写入的字符个数。
考试题:
1 | int i; |
- 每一个格式字符串都耗用两个参数:转换指示符%u所使用的整数值、输出的字符个数
- 问你第三行输出的i用十六进制表示为:64
(5)在大多数复杂指令集计算机架构中,可以按如下方式写一个任意的地址:写入4个字节、递增该地址、写入另外4个字节。这项技术对于覆写目标内存之后的3个字节有一个副作用。
(6)举例
练习题:
1 | unsigned char exploit[1024] = "\x90\x90\x90...\x90"; |
- 考创建的字符串序列格式:四套哑整数/地址对,用于步进参数指针的指令,用于覆写地址的指令。
printf(“\xdc\xf5\x42\x01%08x.%08x.%08x%n”); 还可以将特定的整数值写入地址0x0142f5dc中。参数在放入栈的时候,根据大小从栈顶往栈底放;因此参数开头的地址在栈顶,会被认为是最后的参数,对应%n放入的地方。
进一步地,可以有任意写:对某地址写入4字节、递增该地址、再写入另外4字节。
8.按四个步骤写一个地址
(1)每一次地址递增的时候,都会在低内存中保留一个字节的尾值。这个字节在小尾端架构中是低位字节,而在大尾构中则为高位字节。这个过程可用于通过一系列小整数的值(<255)来实现写一个大整数值(一个地址)的目的。这个过程还可以颠倒过来,即还可以在地址递减时从高位内存写到低位内存。
(2)格式化输出调用仅仅执行每格式字符串的单一写。在对格式化输出函数的单次调用中,还可以执行多次写。
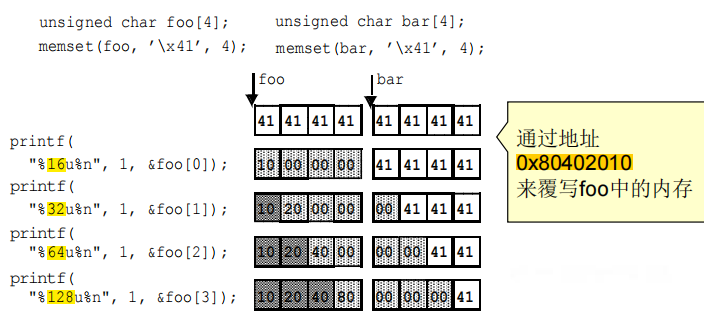
练习题:(这种类似的计算要学会,考过问你写入什么)

- 写入foo的内容为0x80402010(小尾端架构)。在对格式化输出函数的单次调用中执行多次写时,若第一次写入了0x20(%32u%n),第二次想写入0x10,正确的写法是**%240u%n。将多次写与单格式字符串相结合的唯一区别在于,随着每一个字符的输出,计数器的值不断增加。printf(“%16u%n%16u%n%32u%n%64u%n”),第一个%16u%n字符序列向指定地址中写入的值是16,但第二个%16u%n则写32字节,因为计数器没有被重置。**
9.用于覆写一个地址的利用代码
练习题:
1 | static unsigned int already_written, width_field; |
(1)代码使用了三个无符号整数:already_written,width_field,write_byte。变量write_byte中包含下一个将要写入的字节值。already_written用于存储输出的字符个数(应该等于格式化输出函数的输出计数器的值),width_field中存储有转换规范%n所需要的宽度域的值。
(2)所需的宽度是由待写字节的值对0x100(不包括更大的宽度)取模再减去已经输出的字符数。区别在于输出的字符数需要将输出计数器从当前值增加到所需要的值。在每一次写入后,前一个转换规范中的宽度值被加上已写入的字节数。
(3)该代码创建的输出字符串格式为:**%% width u% %n。**
栈随机化
1.背景:在Linux下,栈的起始地址为0xC0000000并且朝低内存方向增长。极少数Linux栈地址中包含空字节,从而容易使它们被插入格式字符串。许多Linux变体中包含有某种栈随机化机制。这种机制使得很难预测栈上信息的位置,包括返回地址和自动变量的位置,这是通过向栈中插入随机的间隙实现的。
2.阻碍栈随机化:尽管栈随机化加大了漏洞利用的难度,但它并不能完全阻止这种情况的发生。例如,格式字符串漏洞利用需要这样的一些值:要覆写的地址,shell code的地址,参数指针和格式字符串起始地址之间的距离,在第一个转换规范%u之前格式化输出函数已经写入的字节数。
3.待覆写地址:可以覆写在程序正常执行中、控制权将被转移到的函数的GOT入口或其他地址。覆写GOT入口的优势在于它独立于诸如栈和堆这样的系统变量。
4.Shellcode的地址:基于Windows的利用中假设向栈的自动变量中插入了一段shellcode。对于实现栈随机化的系统,想找到这个地址很困难。然而shellcode同样可以插入到数据段或堆上的变量中,这就比较容易找到了。
5.距离:攻击者必须确定参数指针和格式字符串的起始位置在栈中的距离。它们之间的相对距离却是不变的。计算参数指针与格式字符串的起始位置之间的距离并且插入所需数目的%x格式转换规范并不难做到。
6.以双字的格式写地址:基于Windows的利用将一个shellcode的地址分成四次每次写入一个字节,各次调用之间对地址进行递增。如果由于对齐的要求或者其他原因造成这种操作不可能,仍然可以通过向地址中一次写入一个字甚至全部内容来实现。
7.Linux利用变体
练习题:exit()函数的GOT入口的地址被覆写为shellcode的地址,所以当调用exit()终止程序时,控制权会移交给shellcode。
1 |
|
8.直接参数存取
(1)Single UNIX规范[IEEE 04]允许转换被应用于参数列表中的格式之后的第n个参数上,而不是应用到下一个未使用的参数上。转换指示符%将被序列所代替,%n$,其中n是一个1到{NL_ARGMAX}范围内的十进制整数,它指定了参数的位置。
(2)格式既可以包含数字式,也可以包含非数字式的参数转换规范,但不允许二者同时出现。数字式的:%n$ and *m$;非数字式的:% and *。%%与%n$混合使用是个例外。在一个格式字符串中混用数字式和非数字式参数规范会导致未定义的结果。
(3)当使用数字式参数规范时,要想指定第n个参数,格式字符串中所有从第一个到第n-1个前导参数都要被指定。在包含有如%n$形式的转换规范的格式字符串中,参数列表中的数字式参数可视需要被从格式字符串中引用多次。
(4)直接参数存取例子
练习题:
1 | int i, j, k = 0; |
- printf(“%4$5u%3$n%5$5u%2$n%6$5u%1$n\n”,&k,&j,&i,5,6,7);
printf(“i=%d,j=%d,k=%d\n”,i,j,k);
对printf()函数的调用导致以5个字符的列宽将值567打印出来。printf()打印出赋给变量i,j,k的值,这些值代表了在上一次调用printf()的基础上输出计数器的增加值。 - 第一个转换规范%4$5u:获得第4个参数(即常量5),并将输出格式化为无符号的十进制整数,宽度为5。
- 第二个转换规范%3$n:将当前输出计数器的值(5)写到第三个参数(&i)所指定的地址。
- %5$5u的作用:获得第5个参数(即常量6),并将输出格式化为无符号的十进制整数,宽度为5。
- %1$n的作用:将当前输出计数器的值(7)写到第一个参数(&k)所指定的地址。
缓解策略
由于现在的代码体系不可能改变库(移除%n),不允许动态格式字符串。
策略:
(1)限制写入字节数。使用%40s而不是%s,可以通过使用更安全的函数实现,比如snprintf、vsnprintf
(2)使用更安全的函数规范
(3)使用静态分析(比如词法分析工具)
(4)静态污点分析
(5)限制可变函数的参数数量(用一个变参控制)
(6)静态二进制分析
1.动态格式字符串
这个程序是可以免于受到格式字符串利用的威胁的:
1 |
|
2.限制字节写入
(1)缓冲区溢出可以通过严格控制这些函数写入的字节数来避免。写入的字节数可以通过指定一个精度域作为%s转换规范的一部分进行控制。例如不使用sprintf(buffer, “Wrong command:%s\n”, user);而是使用sprintf(buffer, “Wrong command:%.495s\n“, user);
(2)精度域指定了针对%s转换所要写入的最大字节数。在这个例子中静态字符串“贡献”了17个字节。精度域为495确保结果字符串可以适合于512字节的缓冲。
(3)另一种方式是使用更安全版本的格式化输出库函数,它们不容易产生缓冲区溢出问题。例如snprintf()比sprintf()更好,vsnprintf()替代vsprintf()。这些函数指定了写入的最大字节数(包括末尾的空字节在内)。
(4)函数asprintf()和vasprintf()可以用于取代sprintf()和vsprintf()。这些函数为字符串分配足够大的空间以容纳包括末尾空字符在内的输出内容,并通过第一个参数返回指向它的指针。这些函数都是GNU的扩展函数,在C或POSIX标准中并没有定义。*BSD系统也支持这些函数。
3.ISO/IEC WDTR 24731
(1)具有增强的安全性的函数:fprintf_s(),printf_s(),snprintf_s(),sprintf(),vfprintf_s(),vprintf_s(),vsnprintf_s(),vsprintf_s().
(2)这些格式化输出函数有着不带_s后缀的原型对应物:不支持格式转换指示符%n;并且如果指针为空的话,它们将其视作约束违例;格式字符串无效。无法防止格式字符串漏洞,这些漏洞使程序崩溃,或被用于查看内存内容。
4.iostream与stdio
(1)C++程序员能够使用iostream库,这个库提供了通过流来实现输入、输出的功能。格式化输出使用iostream依照中级二元插入操作符<<**进行实现。**左操作数是待插入数据的流。右操作数则是要插入的值。**格式化和标记化输入是通过**提取操作符>>实现的。标准的I/O流stdin、stdout和stderr被cin、cout和cerr所取代。
(2)极其不安全的stdio实现
1 |
|
安全的iostream实现
1 |
|
5.测试
(1)很难构建一个能够覆盖所有路径的测试套件。格式字符串bug的主要来源在于错误报告代码。
(2)由于这类代码是作为异常的结果而被触发执行的,因此在实际的运行期测试中这些路径往往被遗漏了。
6.词法分析
(1)pscan工具是一种词法分析工具,可以自动扫描源代码中存在的格式字符串漏洞。它以如下规则扫描格式化输出函数:如果函数最后一个参数是格式字符串且不是静态字符串,则产生一个报告。
(2)无法侦测传入参数时存在的漏洞。它在使用用户或者其他非信任源提供的格式字符串时会产生错误的判断。词法分析工具最主要的优势在于速度。由于词法分析工具缺乏语义知识,导致很多漏洞无法得到检测。
7.静态污点分析
(1)Shankar描述了一个用于检测C程序中的格式字符串安全漏洞的系统,该系统使用了一个基于约束的类型推断引擎。来自非信任源的输入会被标记为污点。而由污点源衍生的数据同样会被标记为污点。对于那些试图将污点数据解释为格式字符串的操作会产生一个警告。这个工具是基于cqual扩展类型修饰符框架而构建的。
(2)污点化利用附加类型修饰符来扩展现有的C类型系统。标准C类型系统中已经包含了const之类的修饰符。增加一个污点修饰符则允许在使用非信任输入的同时将其标记为污点。例如:tainted int getchar();int main(int argc,tainted char argv[])
(3)getchar()的返回值和程序的命令行参数都被标记为污点并作为污点值对待。在给定一套初始污点标注的情况下,就可以推断程序变量能否被赋予来自某个污点源的值。如果任何污点类型的表达式被用作了格式字符串,则用户将会被警告程序中存在潜在的漏洞。
8.调整变参函数的实现
(1)对格式字符串漏洞的利用要求参数指针被步进超过传递给格式化输出函数的参数数目。格式字符串使用的参数个数超过了实际传入的实参数量。可以通过将变参函数的参数个数限制在实际传递的参数个数之内,从而消除这个基于参数指针步进而导致的利用。
(2)通过传递一个终止参数来判断实参什么时候被用尽是不可能的。ANSI变参函数机制允许任意数据作为参数传递。传递参数的数量给可变函数作为参数。
(3)安全的变参函数实现
练习题:
1 |
|
- #define va_start(ap,v):va_start()宏被展开以初始化存储变参个数的变量va_count
- (*(t *)((ap+=_INTSIZEOF(t))-_INTSIZEOF(t)));:展开了va_arg()宏,每次调用它的时候变量va_count都会减1。
- if(va_count– == 0) abort():当va_count等于零时如果再需要参数,则函数失败。当va_arg()函数用尽所有的参数时就非正常终止了。
- av = average(5, 6, 7, 8, -1):works。第一次调用average()的时候,由于函数选用了参数为-1作为终止条件,所以执行成功。
- av = average(5, 6, 7, 8):fails。用户忘记将-1作为参数传给函数。
(4)安全的变参函数绑定
1 | av = average(5, 6, 7, 8); // fails |
9.静态二进制分析
(1)printf()函数应该接受最少2个参数:一个格式化字符串和一个参数。如果printf()只有一个参数并且该参数可变,那么这个调用也许就表示有可利用的漏洞存在。
(2)传递给可变参数函数的参数个数可以通过检查函数的参数修正值进行确定。例如由于栈修正值是4,很明显只有一个参数被传递给了printf()。







